import networkx as nx
## Grafo pequeño 'amistades' (no dirigido)
G = nx.Graph()
G.add_edges_from([
("Ana", "Luis"), ("Ana", "Mia"), ("Luis", "Mia"), ## triángulo (clustering alto)
("Mia", "Jo"), ## puente
("Jo", "Sofi"), ("Jo", "Diego"), ## estrella local en Jo
("Sofi", "Diego"),
("Kai", "Nora") ## componente pequeño aparte
])
print(f"Nodos: {G.number_of_nodes()}, Aristas: {G.number_of_edges()}")Métricas y estructura en una red
Se muestra, paso a paso, cómo construir, medir e interpretar una red pequeña de “amistades”. La meta es que el estudiantado comprenda el sentido de cada métrica—grado, distribución de grado, componentes, centralidades (degree, closeness, betweenness), clustering, caminos más cortos, comunidades y modularidad—y aprenda a comunicar hallazgos de modo claro.
Primero se construye una red muy pequeña y significativa (triángulos, puentes y un componente aislado). Luego se miden métricas clave y se interpreta qué nos dice cada una sobre la estructura.
1 Ejemplo
1.1 Construcción de la red
Creamos un grafo no dirigido de “amistades”. El diseño incluye:
Un triángulo (Ana–Luis–Mia) para ilustrar clustering alto.
Un puente (Mia–Jo) que conecta dos zonas y eleva la intermediación.
Un componente aislado (Kai–Nora) para discutir alcanzabilidad.
Lectura esperada. Verás el número de nodos y aristas.
La red no es conexa: habrá un componente principal (con Ana, Luis, Mia, Jo, Sofi, Diego) y un componente de tamaño 2 (Kai–Nora).
1.2 Grado y distribución de grado
El grado de un nodo es el número de enlaces que tiene.
La distribución de grado describe cómo se reparte esa conectividad: ¿muchos con pocos enlaces y pocos con muchos? ¿o todos similares?
import numpy as np
deg = dict(G.degree())
grados = np.array(list(deg.values()))
print("Grado por nodo:", deg)
print("Grado medio:", grados.mean(), " | Mediana:", np.median(grados), " | Máx:", grados.max())Interpretación.
- Grado por nodo: identifica quiénes son los más conectados (p. ej., Jo debería destacar).
- Media y mediana: si son cercanas, la conectividad típica es relativamente homogénea; si difieren, hay asimetría.
- Máximo: indica posibles nodos clave (“hubs” locales) por cantidad de conexiones.
Para informe: “La distribución de grado muestra un nodo con conectividad superior (Jo), mientras que el triángulo (Ana–Luis–Mia) presenta grados intermedios y homogéneos.”
1.3 Componentes conexos
Un componente conexo es un subgrafo donde todos los nodos pueden alcanzarse entre sí siguiendo aristas. La presencia de múltiples componentes indica subredes aisladas.
componentes = list(nx.connected_components(G))
print(f"Componentes: {len(componentes)}")
for i, comp in enumerate(componentes, start=1):
print(f" - C{i}: {sorted(comp)}")Interpretación.
El componente {Kai, Nora} no es alcanzable desde el resto: una situación típica en redes reales (fragmentación).
En análisis de distancias (closeness/ASP/diámetro), se suele trabajar con el componente gigante (el más grande).
1.4 Centralidades: grado, cercanía y betweenness
Grado (degree): cuántos vecinos directos (popularidad local).
Cercanía (closeness): inversa de la suma de distancias a los demás (eficiencia de acceso).
Intermediación (betweenness): fracción de caminos más cortos que pasan por un nodo (rol de puente).
c_deg = nx.degree_centrality(G)
c_clo = nx.closeness_centrality(G) ## cercanía: acceso promedio (ojo con múltiples componentes)
c_bet = nx.betweenness_centrality(G) ## intermediación: “puentes” estructurales
print("Centralidad de grado:", c_deg)
print("Centralidad de cercanía:", c_clo)
print("Centralidad de intermediación:", c_bet)Interpretación.
- Jo debe tener degree alto (varios vecinos) y betweenness elevada por su rol conectando el triángulo con Sofi/Diego.
- En redes no conexas, la closeness de nodos fuera del gigante tiende a ser menor (gran parte de la red no es alcanzable).
Para informe: “La intermediación resalta a Jo como nodo puente; si se remueve, la red se fragmenta más.”
1.5 Clustering (transitividad local)
El clustering local de un nodo mide la propensión a formar triángulos entre sus vecinos. El promedio resume la “triangulación” global.
clust_local = nx.clustering(G) ## probabilidad de triángulo alrededor de cada nodo
clust_prom = nx.average_clustering(G)
print("Clustering local:", clust_local)
print("Clustering promedio:", clust_prom)Interpretación.
- En el triángulo (Ana–Luis–Mia), el clustering local es alto (sus vecindarios están muy conectados).
- Nodos tipo “puente” (p. ej., Jo) suelen tener clustering más bajo: sus vecinos no están todos conectados entre sí.
1.6 Caminos más cortos: ASP y diámetro (en el componente gigante)
ASP (average shortest path): longitud promedio de camino mínimo entre pares de nodos.
Diámetro: máxima distancia más corta entre cualquier par dentro del componente.
## Nota: average_shortest_path_length requiere grafo conexo
Gcc = G.subgraph(max(nx.connected_components(G), key=len)).copy()
asp = nx.average_shortest_path_length(Gcc)
diam = nx.diameter(Gcc)
print("Longitud promedio de camino (ASP):", asp)
print("Diámetro (máx. distancia más corta):", diam)Interpretación.
ASP bajo sugiere buena conectividad interna (acceso eficiente).
El diámetro muestra el “peor caso” de proximidad estructural dentro del componente principal.
1.7 Comunidades y modularidad (Q)
Buscamos grupos (comunidades) con más conexiones dentro que entre grupos. La modularidad Q evalúa cuán marcada es esa división (valores más altos ≈ comunidades más definidas).
from networkx.algorithms import community as nxcom
coms = nxcom.greedy_modularity_communities(G) ## heurística por modularidad
Q = nxcom.modularity(G, coms)
print("Comunidades (greedy):", [sorted(list(c)) for c in coms])
print("Modularidad Q:", Q)Interpretación.
- Esperamos una comunidad {Ana, Luis, Mia, Jo, Sofi, Diego} y otra {Kai, Nora}.
- Un Q moderado/alto indicará que estas comunidades están bien separadas.
1.8 Ilustración (opcional)
Es útil ver la estructura: triángulo, puente y componente aislado. El layout por resorte (spring) coloca más cerca a quienes están conectados.
import matplotlib.pyplot as plt
pos = nx.spring_layout(G, seed=42)
plt.figure()
nx.draw_networkx(G, pos=pos, with_labels=True, node_size=800)
plt.title("Red sintética de amistades (ilustración)")
plt.axis("off")
## plt.show()Lectura visual. Identifica:
Triángulos (alta transitividad).
Puentes (cuellos de botella potenciales).
Subredes aisladas (componentes).
Estructura: red pequeña con triangulación local (Ana–Luis–Mia), un puente (Mia–Jo) y un componente aislado (Kai–Nora).
Conectividad: la distribución de grado revela un nodo central (Jo) y varios de grado medio.
Centralidades: betweenness destaca el rol estratégico de Jo; closeness es mayor en nodos bien ubicados dentro del componente principal.
Clustering: alto en el triángulo, bajo en puentes.
Distancias: ASP y diámetro razonables para una red chica; análisis restringido al componente gigante.
Comunidades: partición coherente; Q confirma grupos con densidad interna superior.
Conclusión. La red ilustra patrones típicos de redes sociales: círculos cerrados (triángulos), nodos puente que facilitan el flujo entre grupos, y subredes aisladas. Las métricas cuantifican estas intuiciones y permiten justificar por qué ciertos nodos son “clave”.
2 ☕ Red empírica: Cafés en Bogotá
En esta segunda parte aplicamos las mismas métricas a una red real de cafés en Bogotá,
construida a partir de sus coordenadas geográficas y la relación de vecindad espacial.
Objetivo: analizar la estructura local (grado, clustering) y global (componentes, caminos, comunidades)
de la red de cafeterías, identificando patrones de concentración o aislamiento.
2.1 Construcción del grafo de proximidad
Los datos provienen de una búsqueda en Google Places o Yelp, exportados como cafes_bogota.csv.
Cada fila representa un café con sus coordenadas (lat, lon), nombre, calificación (rating) y número de reseñas.
Se construye la red con el modelo de vecinos más cercanos (k-NN) usando la distancia haversine (en radianes).
import pandas as pd
import numpy as np
import networkx as nx
from sklearn.neighbors import NearestNeighbors
# Datos locales
df = pd.read_csv("cafes_bogota.csv")
coords = np.radians(df[["lat","lon"]].dropna().to_numpy())
k = 6 # número de vecinos cercanos
# Modelo k-NN
nbrs = NearestNeighbors(n_neighbors=k+1, metric="haversine").fit(coords)
dist, idx = nbrs.kneighbors(coords)
# Construcción del grafo no dirigido
G_cafe = nx.Graph()
for i, row in df.dropna(subset=["lat","lon"]).reset_index(drop=True).iterrows():
G_cafe.add_node(i, nombre=row["nombre"], rating=row["rating"])
for i in range(len(coords)):
for jpos in idx[i,1:]:
j = int(jpos)
if i != j:
G_cafe.add_edge(i, j)
print(f"Nodos: {G_cafe.number_of_nodes()} | Aristas: {G_cafe.number_of_edges()}")Interpretación.
Cada nodo representa un café y cada arista une dos cafés espacialmente próximos. En esta red, los cafés no se enlazan “por amistad”, sino por proximidad geográfica (distancia corta). El parámetro k controla la densidad del grafo: valores mayores → más conexiones.
2.2 Grado y distribución de grado
El grado mide cuántos cafés están cerca de cada uno. El promedio, la mediana y el máximo resumen el nivel de conectividad local.
deg_cafe = dict(G_cafe.degree())
grados = np.array(list(deg_cafe.values()))
print("Grado medio:", grados.mean(), "| Mediana:", np.median(grados), "| Máx:", grados.max())Si el promedio es cercano a 2k/2 = k (por simetrización de aristas), la estructura es regular. Un grado máximo alto puede señalar nodos centrales en zonas densas (como Chapinero o Teusaquillo).
Interpretación: “En promedio, cada café se conecta con 8 vecinos cercanos, indicando un tejido urbano denso pero no saturado. Algunos cafés alcanzan grados de hasta 15, lo que sugiere zonas de alta concentración.”
2.3 Componentes conexos
Verifica si todos los cafés están conectados o si existen subredes aisladas (p. ej., en periferias).
componentes = list(nx.connected_components(G_cafe))
print(f"Componentes: {len(componentes)} (tamaños: {[len(c) for c in componentes]})")Interpretación.
- Una única componente grande implica continuidad espacial (toda la red está conectada).
- Varias componentes pequeñas indican aislamiento geográfico o zonas sin cafés cercanos.
2.4 Centralidades: grado, cercanía y betweenness
Miden diferentes aspectos de “importancia” estructural:
Degree centrality: popularidad local (muchos vecinos).
Closeness: accesibilidad global (corto promedio de distancias).
Betweenness: rol de puente o intermediario entre zonas.
c_deg = nx.degree_centrality(G_cafe)
c_clo = nx.closeness_centrality(G_cafe)
c_bet = nx.betweenness_centrality(G_cafe, normalized=True)
top_bet = sorted(c_bet.items(), key=lambda x: x[1], reverse=True)[:5]
print("Top-5 cafés por betweenness:", top_bet)Interpretación.
Los cafés con alto grado suelen estar en zonas densas o turísticas.
Los de alta betweenness funcionan como “puentes urbanos” que enlazan barrios o conglomerados.
En términos prácticos, pueden ser puntos estratégicos de flujo (visibles o de referencia).
2.5 Clustering promedio
El clustering mide la probabilidad de que dos vecinos de un café también sean vecinos entre sí: una forma de “densidad local” o microcomunidad.
clust_prom = nx.average_clustering(G_cafe)
print("Clustering promedio:", clust_prom)Interpretación.
Un clustering medio-alto indica que los cafés tienden a agruparse (zonas comerciales).
Un clustering bajo refleja dispersión: cafés aislados o en avenidas principales.
2.6 6. Caminos más cortos y diámetro (componente gigante)
Los caminos mínimos permiten evaluar la conectividad global: qué tan fácil es moverse de un café a otro dentro de la red principal.
Gcc = G_cafe.subgraph(max(nx.connected_components(G_cafe), key=len)).copy()
asp = nx.average_shortest_path_length(Gcc)
diam = nx.diameter(Gcc)
print("Longitud promedio de camino (ASP):", asp, "| Diámetro:", diam)Interpretación.
Un ASP bajo implica una red bien interconectada (pocos saltos promedio).
El diámetro muestra la máxima separación efectiva entre cafés conectados.
Valores altos pueden indicar zonas periféricas o fragmentación.
2.7 Comunidades y modularidad
Usamos el algoritmo greedy de modularidad para detectar agrupamientos espaciales: barrios o sectores donde los cafés están más interconectados entre sí que con el resto.
from networkx.algorithms import community as nxcom
coms = nxcom.greedy_modularity_communities(G_cafe)
Q = nxcom.modularity(G_cafe, coms)
print("Comunidades:", len(coms), "| Modularidad Q:", Q)Interpretación.
Si ( Q ) es alto (>0.3), las comunidades están bien diferenciadas.
Cada grupo puede corresponder a una zona geográfica con cafés cercanos (ej. “Chapinero Alto”, “Zona T”, “La Candelaria”).
Esta métrica resume fragmentación urbana o patrones de concentración.
2.8 Distribución de grados: histograma y CDF
Estos gráficos permiten visualizar la forma de la conectividad.
import matplotlib.pyplot as plt
bins = range(grados.min(), grados.max()+2)
plt.figure()
plt.hist(grados, bins=bins, align='left', rwidth=0.85)
plt.xlabel("Grado (vecinos)")
plt.ylabel("Frecuencia de cafés")
plt.title("Distribución de grado — Red de cafés en Bogotá")
plt.grid(True, alpha=0.3)
# plt.show()# CDF del grado
gr_sorted = np.sort(grados)
cdf = np.arange(1, len(gr_sorted)+1) / len(gr_sorted)
plt.figure()
plt.step(gr_sorted, cdf, where='post')
plt.xlabel("Grado")
plt.ylabel("Proporción acumulada")
plt.title("CDF del grado — Red de cafés")
plt.grid(True, alpha=0.3)
# plt.show()Lectura.
La moda del histograma muestra el grado típico (conectividad habitual).
La cola derecha revela cafés muy conectados (zonas densas).
La CDF permite comparar diferentes valores de
k: al aumentark, las curvas se desplazan a la derecha (mayor grado promedio).
2.9 Tabla de cafés “clave” según centralidades
Listamos los cafés con mayor centralidad por grado, cercanía o betweenness.
import pandas as pd
top = pd.DataFrame({
"nombre": [G_cafe.nodes[i]["nombre"] for i in G_cafe.nodes()],
"grado": [deg_cafe[i] for i in G_cafe.nodes()],
"deg_centrality": [c_deg[i] for i in G_cafe.nodes()],
"closeness": [c_clo[i] for i in G_cafe.nodes()],
"betweenness": [c_bet[i] for i in G_cafe.nodes()],
})
print(top.sort_values("betweenness", ascending=False).head(10))Interpretación.
Estos nodos son los más influyentes o estratégicos según la métrica:
Alto grado: muchos cafés vecinos inmediatos.
Alta closeness: posición “central” (acceso eficiente).
Alta betweenness: conectan distintas zonas (puentes geográficos).
Mundano Coffee Shop — betweenness 0.456, grado 6, closeness 0.234 Broker puro: enlace crítico entre clusters. No es el más conectado, pero articula zonas. Si lo quitas, es probable que aumenten las distancias entre partes de la red.
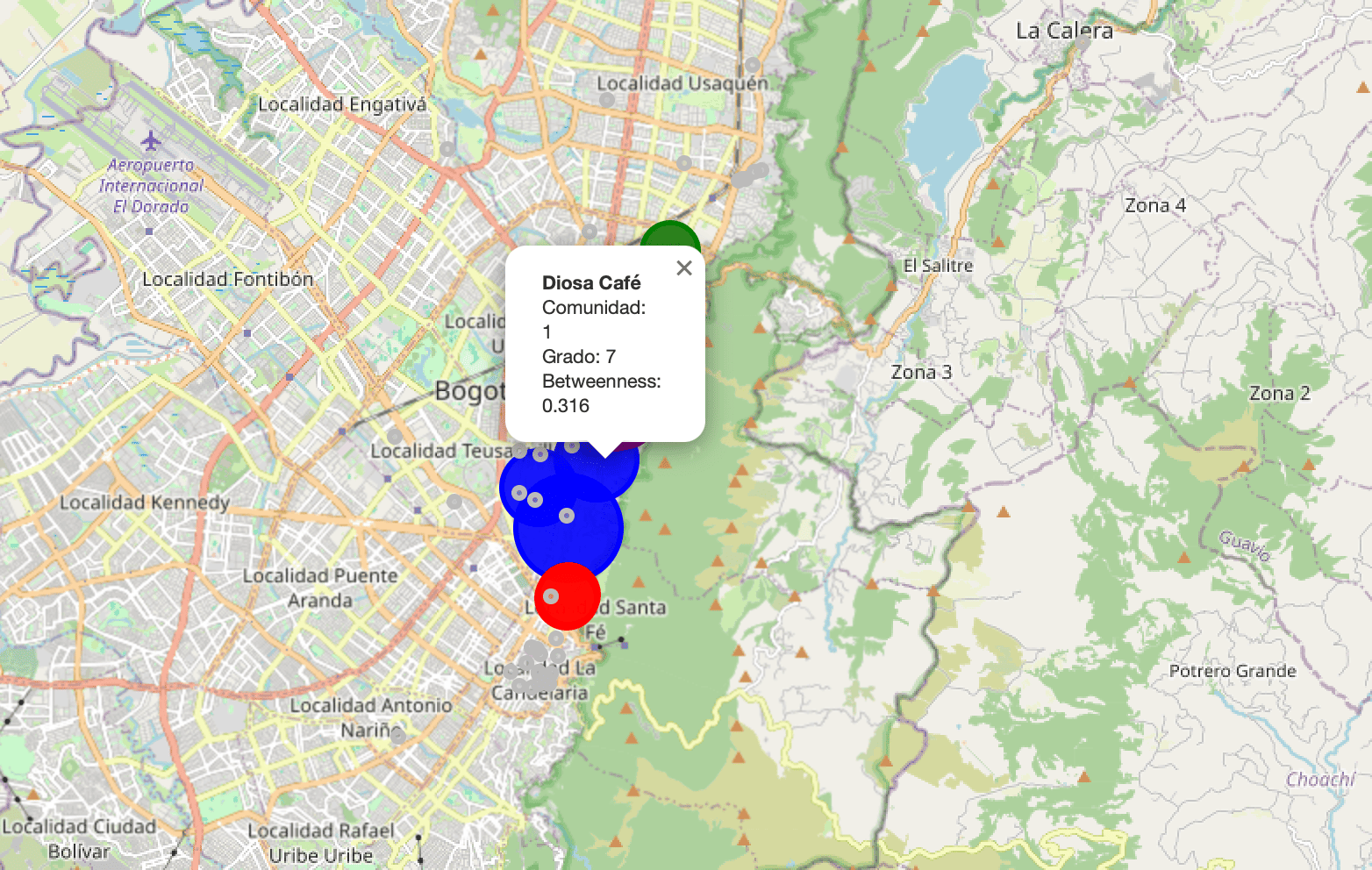
Diosa Café — 0.316, grado 7, closeness 0.253 También puente importante, con buena cercanía (posición bastante central). Combina rol articulador con accesibilidad global.
Bogota Coffee Roasters / Casa & Jardín — 0.294, grado 10 (alto), closeness 0.249 Doble rol: hub local (muchos vecinos) y broker (intermediación alta). Es un punto estratégico para difusión/visibilidad.
Café Amor Perfecto Chapinero Alto — 0.265, grado 8, closeness 0.250 Muy bien posicionado espacialmente (closeness alta) y con buen poder de articulación. Candidato a “ancla” en su zona.
Tropicalia Coffee — 0.231, grado 7, closeness 0.219 Puente secundario: menos central que los anteriores en distancia media, pero relevante conectando subgrupos.
Open Chapinero Café — 0.224, grado 8, closeness 0.250 Perfil similar a Amor Perfecto: accesible (closeness alta) y con intermediación relevante. Buen nodo para “rutas” entre clusters.
Agüita Negra / Valiente / Nuestro Café — 0.190–0.211, grado 7, closeness ~0.216–0.222 Articuladores locales: sostienen conexiones entre vecindarios adyacentes; su remoción probablemente alargaría ciertos caminos.
Café 18 – El Chicó — 0.182, grado 10, closeness 0.181 (baja) Hub de barrio: muchos enlaces dentro de un cluster denso, pero menos central globalmente; no es el principal puente entre zonas. Gran capacidad local, menor influencia en rutas largas.
2.9.1 Conclusiones claras
Puentes vs. Hubs:
- Mundano y Diosa destacan como puentes (alta betweenness con grado moderado).
- Bogota Coffee Roasters y Café 18 – El Chicó son más hubs (grado alto); el primero también puente, el segundo sobre todo local.
Ubicación global (closeness): Valores ~0.24–0.25 (Amor Perfecto, Open Chapinero, Diosa) sugieren buen acceso promedio al resto; pueden servir como puntos “centrales” para recorridos.
Estrategia práctica:
Para difusión (campañas, rutas turísticas, eventos): prioriza Corredores con buena cercanía (Diosa, Amor Perfecto, Open Chapinero).
Para cobertura local en zonas densas: usa hubs como Bogota Coffee Roasters o Café 18 – El Chicó.
Sensibilidad al parámetro k:
Estos resultados dependen de k (vecinos). Si subes k, suelen bajar algunas betweenness (más rutas alternativas) y sube el grado medio. Vale la pena comparar con k=4 y k=8.
3 Código completo
# ============================================================
# 🌱 PARTE 1 — RED SINTÉTICA DE “AMISTADES”
# ============================================================
import networkx as nx
import numpy as np
import matplotlib.pyplot as plt
from networkx.algorithms import community as nxcom
# 1️⃣ Crear grafo pequeño (amistades)
G = nx.Graph()
G.add_edges_from([
("Ana", "Luis"), ("Ana", "Mia"), ("Luis", "Mia"), # triángulo
("Mia", "Jo"), # puente
("Jo", "Sofi"), ("Jo", "Diego"), # estrella local
("Sofi", "Diego"),
("Kai", "Nora") # componente aislado
])
print(f"Nodos: {G.number_of_nodes()}, Aristas: {G.number_of_edges()}")
# 2️⃣ Grado y distribución
deg = dict(G.degree())
grados = np.array(list(deg.values()))
print("Grado por nodo:", deg)
print("Grado medio:", grados.mean(), " | Mediana:", np.median(grados), " | Máx:", grados.max())
# 3️⃣ Componentes conexos
componentes = list(nx.connected_components(G))
print(f"\nComponentes: {len(componentes)}")
for i, comp in enumerate(componentes, start=1):
print(f" - C{i}: {sorted(comp)}")
# 4️⃣ Centralidades
c_deg = nx.degree_centrality(G)
c_clo = nx.closeness_centrality(G)
c_bet = nx.betweenness_centrality(G)
print("\nTop-3 por betweenness:", sorted(c_bet.items(), key=lambda x: x[1], reverse=True)[:3])
# 5️⃣ Clustering
clust_local = nx.clustering(G)
clust_prom = nx.average_clustering(G)
print("\nClustering promedio:", clust_prom)
# 6️⃣ Caminos más cortos (componente gigante)
Gcc = G.subgraph(max(nx.connected_components(G), key=len)).copy()
asp = nx.average_shortest_path_length(Gcc)
diam = nx.diameter(Gcc)
print("ASP:", asp, "| Diámetro:", diam)
# 7️⃣ Comunidades y modularidad
coms = nxcom.greedy_modularity_communities(G)
Q = nxcom.modularity(G, coms)
print("\nComunidades:", [sorted(list(c)) for c in coms])
print("Modularidad Q:", Q)
# 8️⃣ Visual
pos = nx.spring_layout(G, seed=42)
plt.figure(figsize=(6,4))
nx.draw_networkx(G, pos=pos, with_labels=True, node_color="lightblue", node_size=800)
plt.title("Red sintética de amistades")
plt.axis("off")
plt.show()
# ============================================================
# ☕ PARTE 2 — RED EMPÍRICA DE CAFÉS EN BOGOTÁ
# ============================================================
import pandas as pd
from sklearn.neighbors import NearestNeighbors
# 1️⃣ Cargar datos locales (exportados de Google Places)
# Asegúrate de tener 'cafes_bogota.csv' en tu entorno de Colab
df = pd.read_csv("cafes_bogota.csv")
print(df.shape)
print(df.head(3))
# 2️⃣ Crear grafo de proximidad k-NN (Haversine)
coords = np.radians(df[["lat","lon"]].dropna().to_numpy())
k = 6 # número de vecinos cercanos
nbrs = NearestNeighbors(n_neighbors=k+1, metric="haversine").fit(coords)
dist, idx = nbrs.kneighbors(coords)
G_cafe = nx.Graph()
for i, row in df.dropna(subset=["lat","lon"]).reset_index(drop=True).iterrows():
G_cafe.add_node(i, nombre=row["nombre"], rating=row["rating"])
for i in range(len(coords)):
for jpos in idx[i,1:]:
j = int(jpos)
if i != j:
G_cafe.add_edge(i, j)
print(f"\nNodos: {G_cafe.number_of_nodes()} | Aristas: {G_cafe.number_of_edges()}")
# 3️⃣ Métricas básicas
deg_cafe = dict(G_cafe.degree())
grados = np.array(list(deg_cafe.values()))
print("Grado medio:", grados.mean(), "| Mediana:", np.median(grados), "| Máx:", grados.max())
# 4️⃣ Componentes
componentes = list(nx.connected_components(G_cafe))
print(f"Componentes: {len(componentes)} (tamaños: {[len(c) for c in componentes]})")
# 5️⃣ Centralidades
c_deg = nx.degree_centrality(G_cafe)
c_clo = nx.closeness_centrality(G_cafe)
c_bet = nx.betweenness_centrality(G_cafe, normalized=True)
top_bet = sorted(c_bet.items(), key=lambda x: x[1], reverse=True)[:5]
print("\nTop-5 cafés por betweenness:", top_bet)
# 6️⃣ Clustering
clust_prom = nx.average_clustering(G_cafe)
print("Clustering promedio:", clust_prom)
# 7️⃣ Caminos más cortos y diámetro (componente gigante)
Gcc = G_cafe.subgraph(max(nx.connected_components(G_cafe), key=len)).copy()
asp = nx.average_shortest_path_length(Gcc)
diam = nx.diameter(Gcc)
print("ASP:", asp, "| Diámetro:", diam)
# 8️⃣ Comunidades y modularidad
coms = nxcom.greedy_modularity_communities(G_cafe)
Q = nxcom.modularity(G_cafe, coms)
print("Comunidades detectadas:", len(coms), "| Modularidad Q:", Q)
# 9️⃣ Histogramas y CDF de grados
bins = range(grados.min(), grados.max()+2)
plt.figure(figsize=(6,4))
plt.hist(grados, bins=bins, align='left', rwidth=0.85, color="tan")
plt.xlabel("Grado (número de vecinos)")
plt.ylabel("Frecuencia de cafés")
plt.title("Distribución de grado — Red de cafés en Bogotá")
plt.grid(True, alpha=0.3)
plt.show()
gr_sorted = np.sort(grados)
cdf = np.arange(1, len(gr_sorted)+1) / len(gr_sorted)
plt.figure(figsize=(6,4))
plt.step(gr_sorted, cdf, where='post', color="brown")
plt.xlabel("Grado")
plt.ylabel("Proporción acumulada")
plt.title("CDF del grado — Red de cafés")
plt.grid(True, alpha=0.3)
plt.show()
# 🔟 Tabla de cafés clave
top = pd.DataFrame({
"nombre": [G_cafe.nodes[i]["nombre"] for i in G_cafe.nodes()],
"grado": [deg_cafe[i] for i in G_cafe.nodes()],
"deg_centrality": [c_deg[i] for i in G_cafe.nodes()],
"closeness": [c_clo[i] for i in G_cafe.nodes()],
"betweenness": [c_bet[i] for i in G_cafe.nodes()],
})
print("\nTop-10 cafés por betweenness:")
print(top.sort_values("betweenness", ascending=False).head(10))