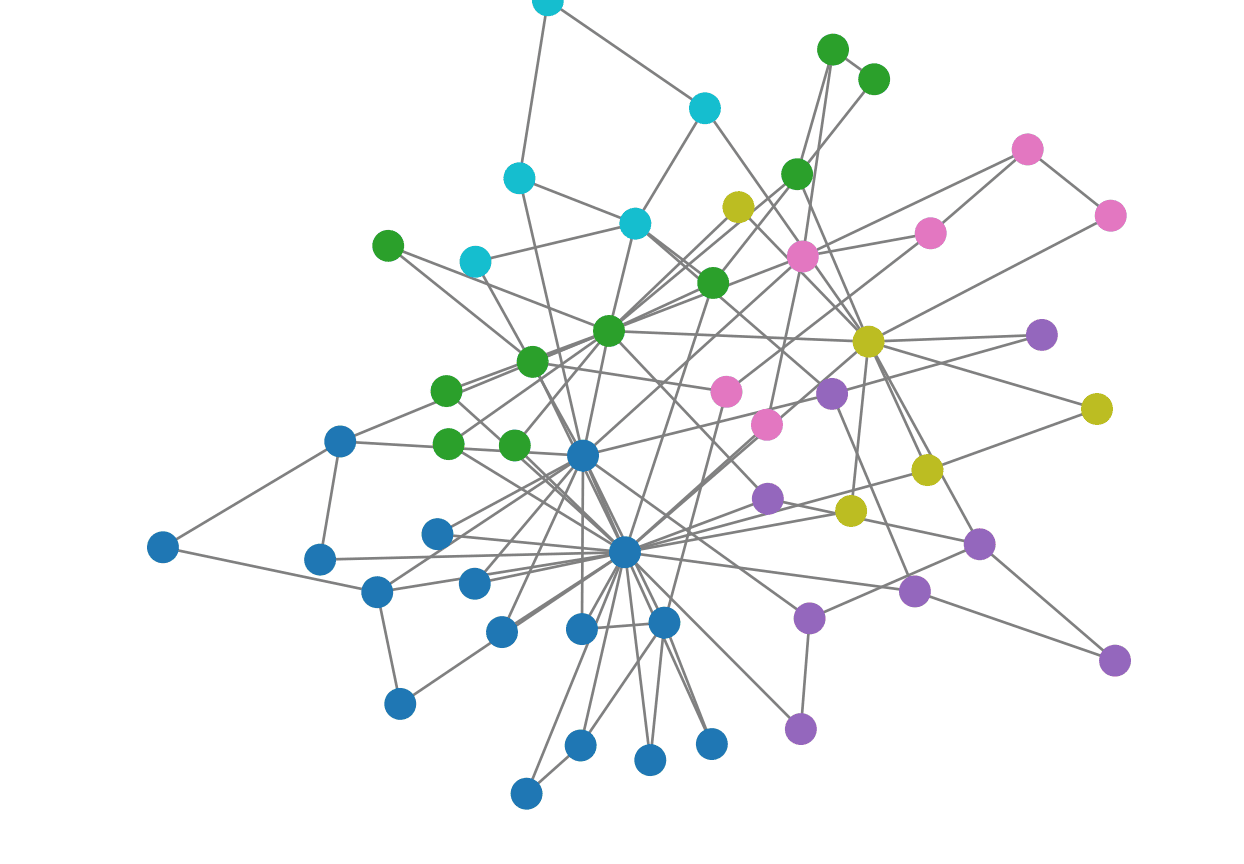
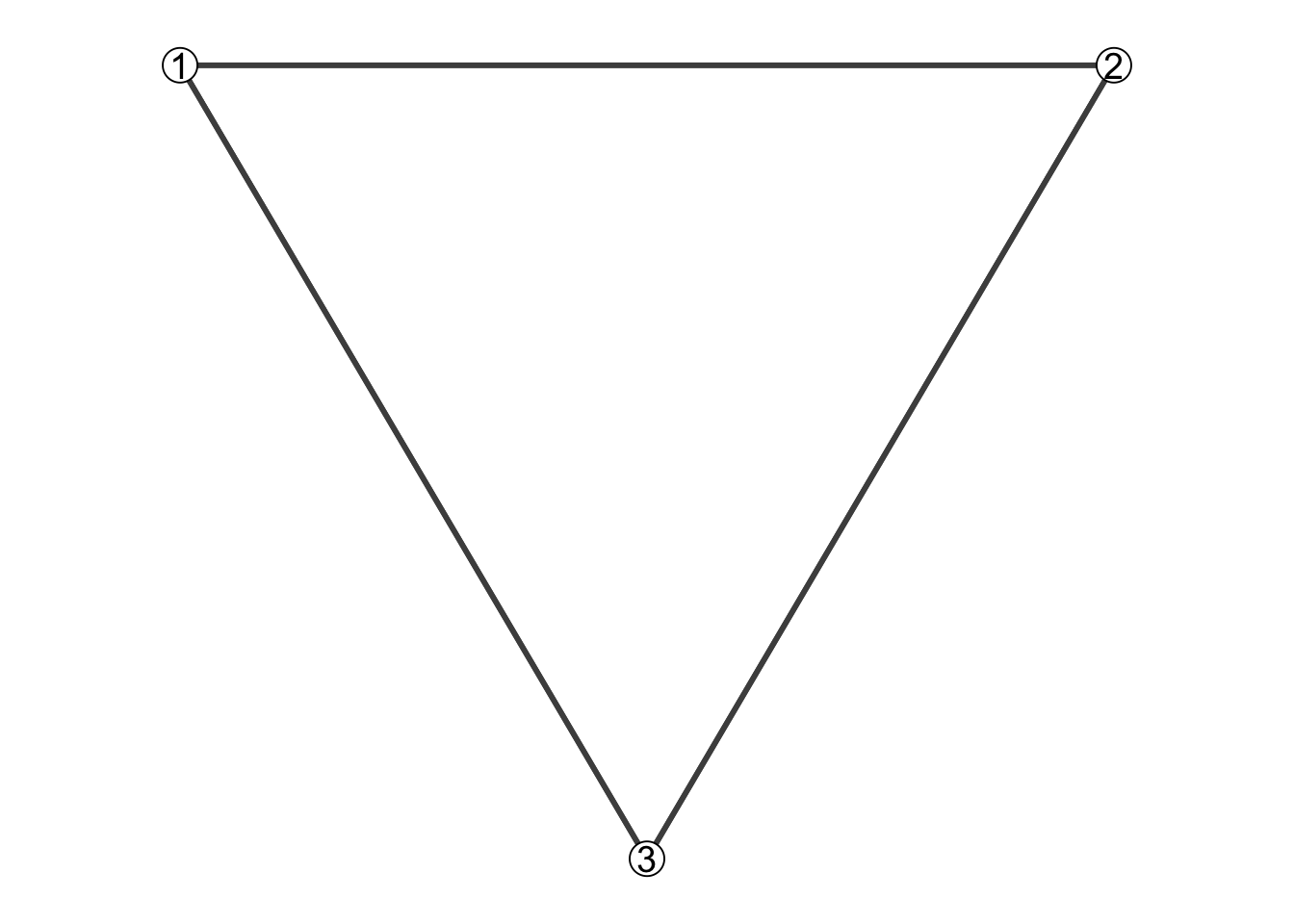
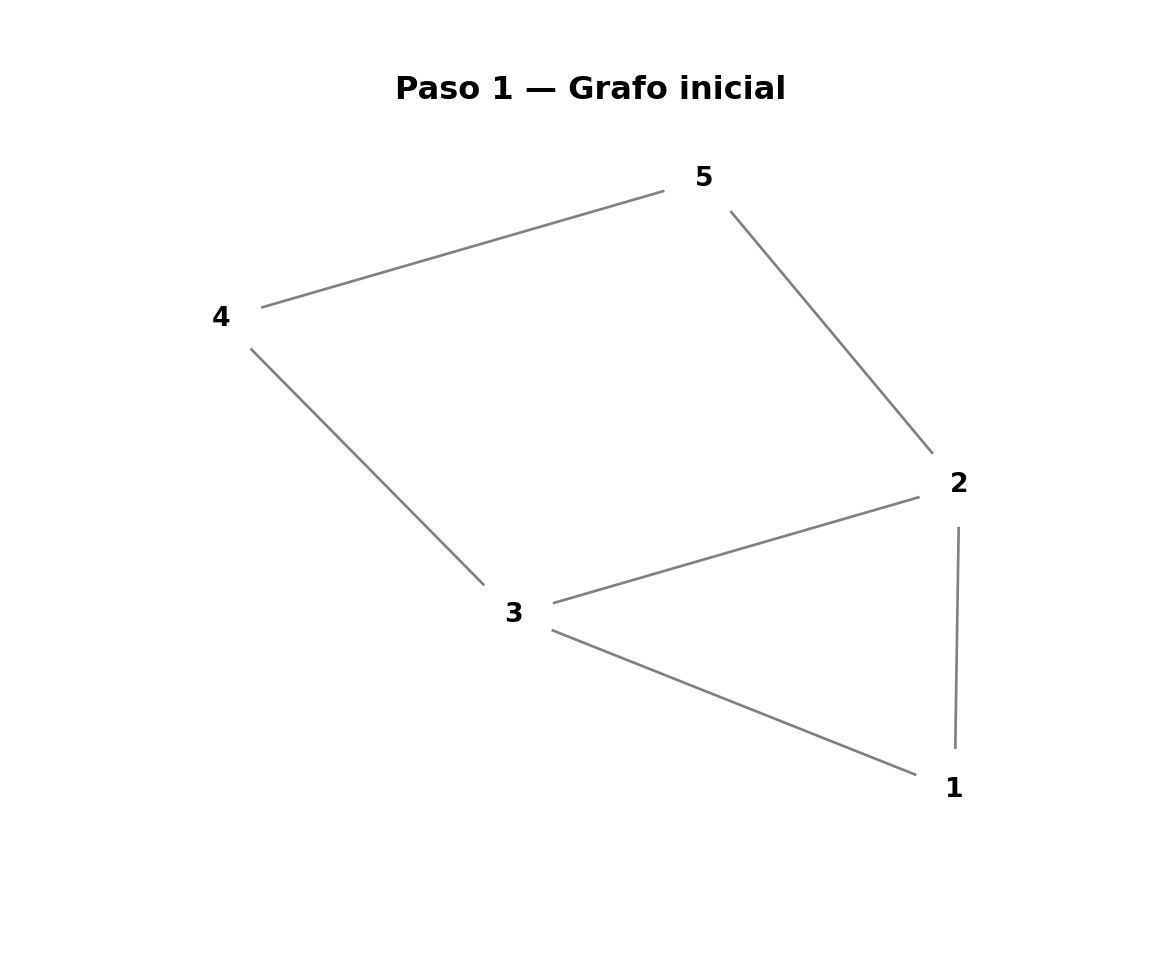
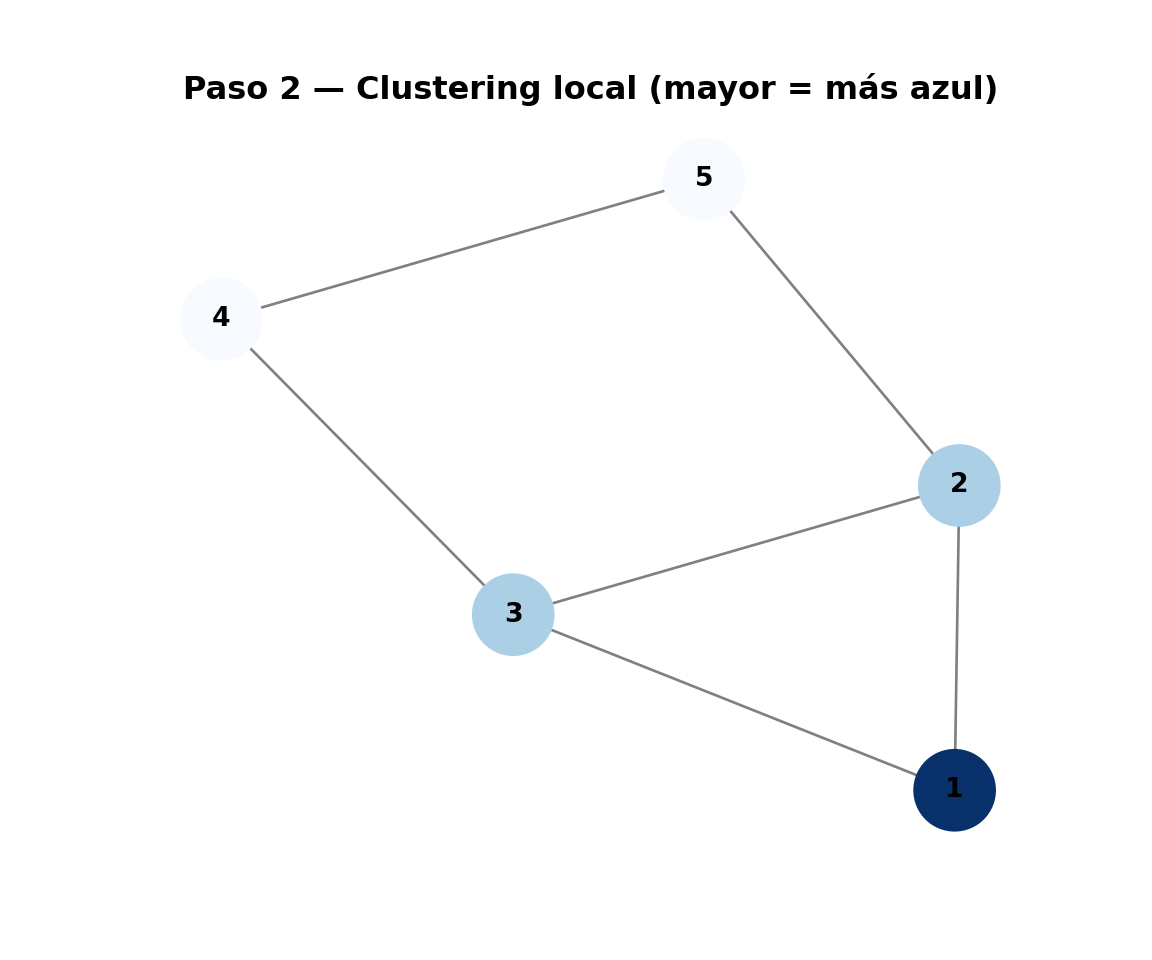
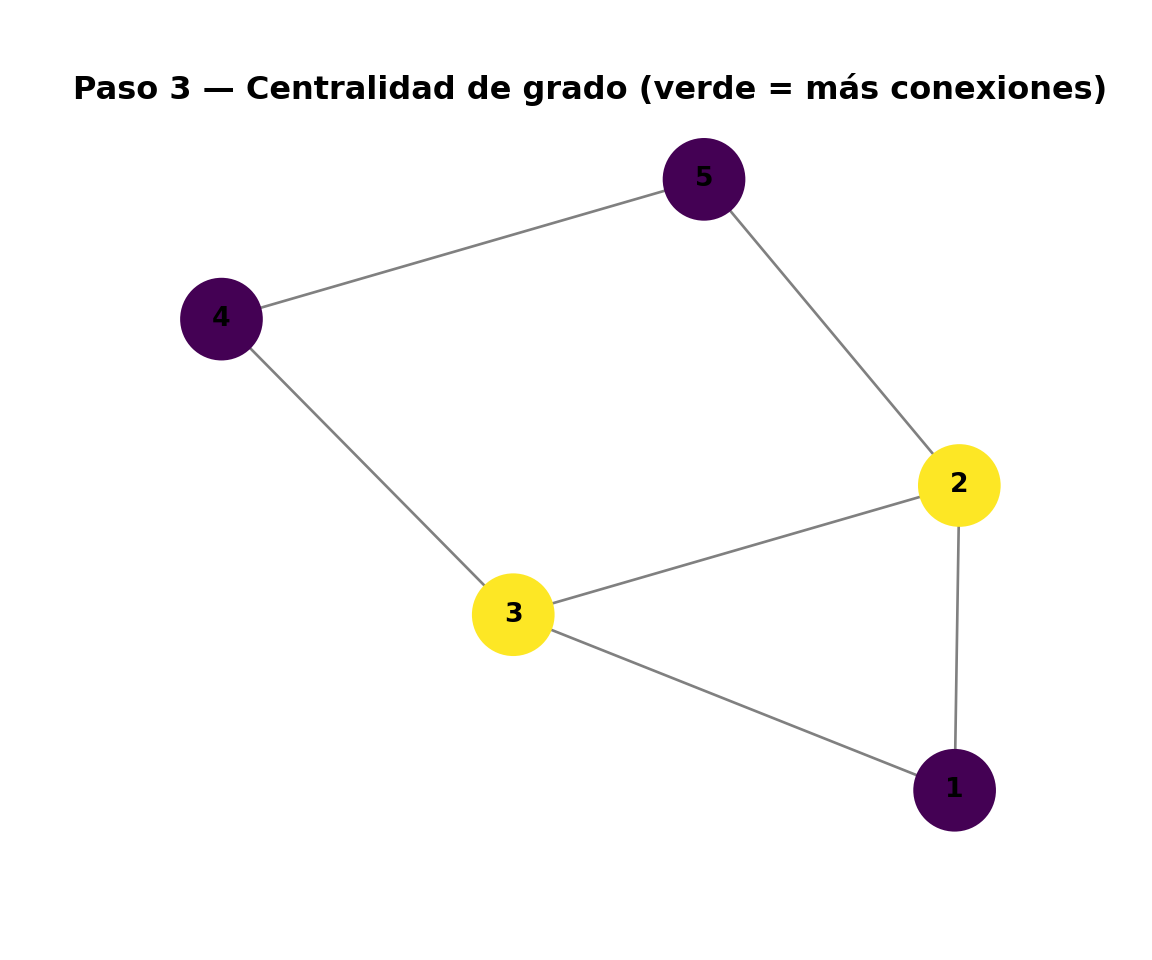
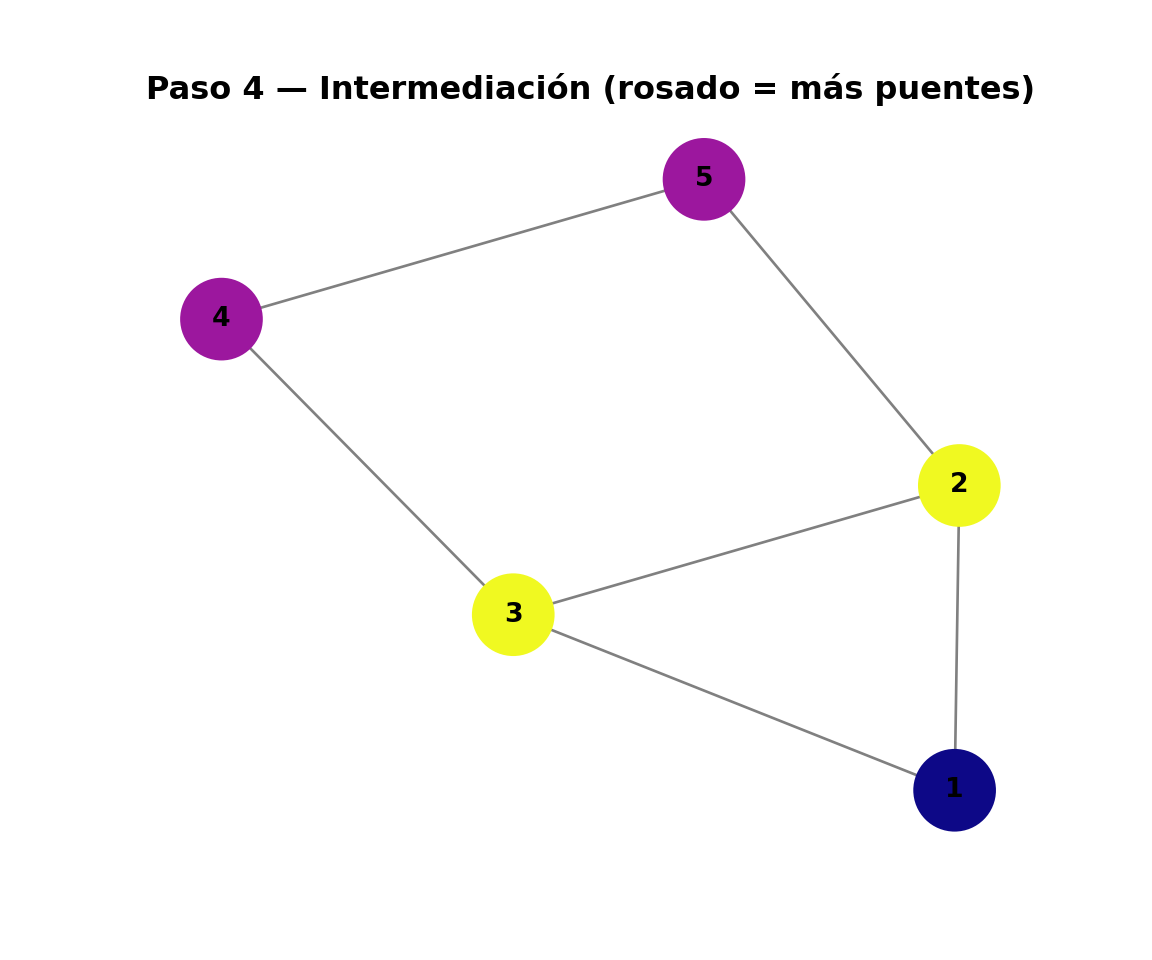
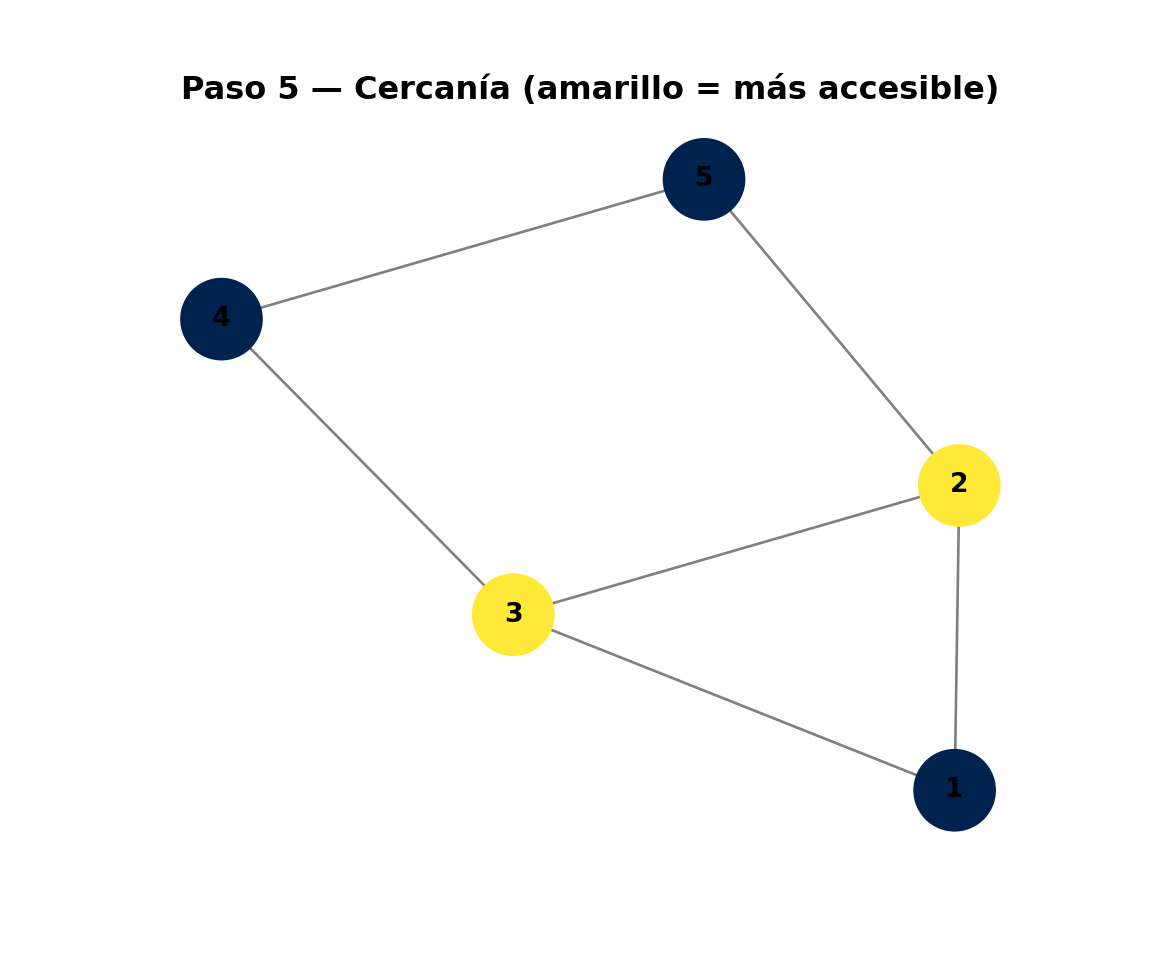
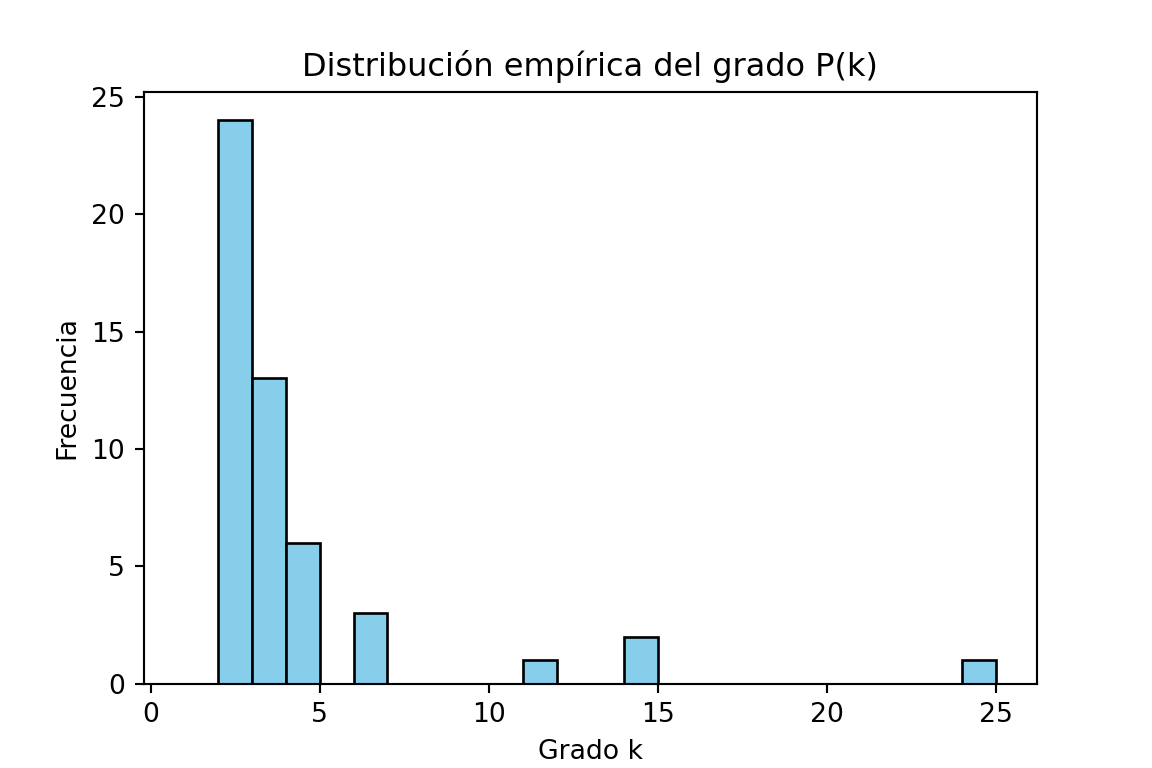
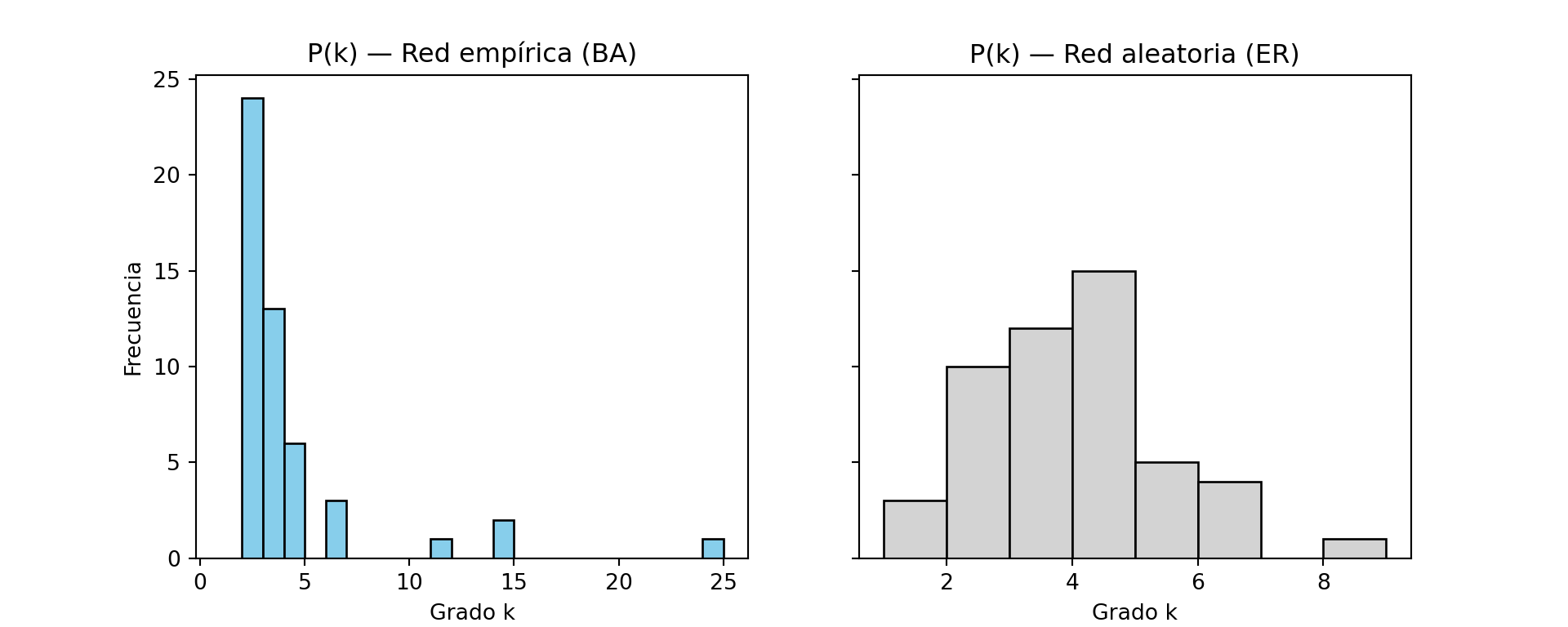
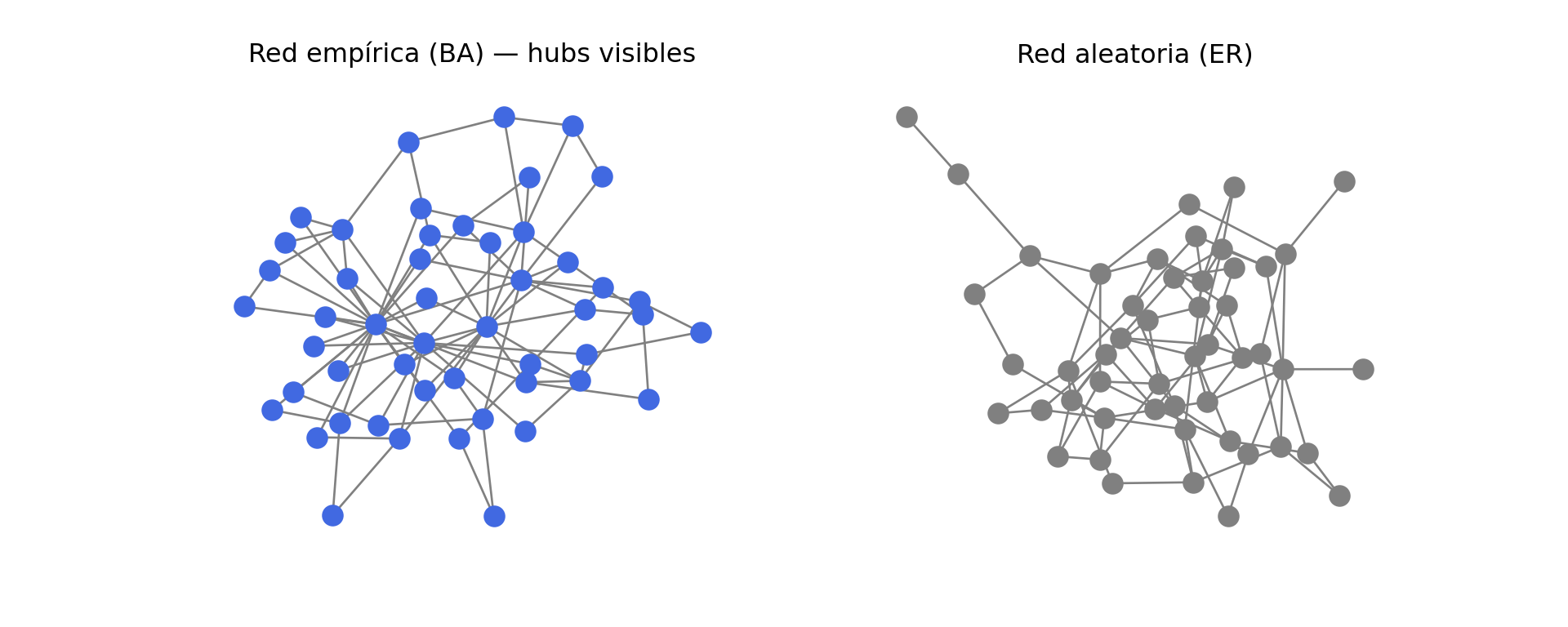
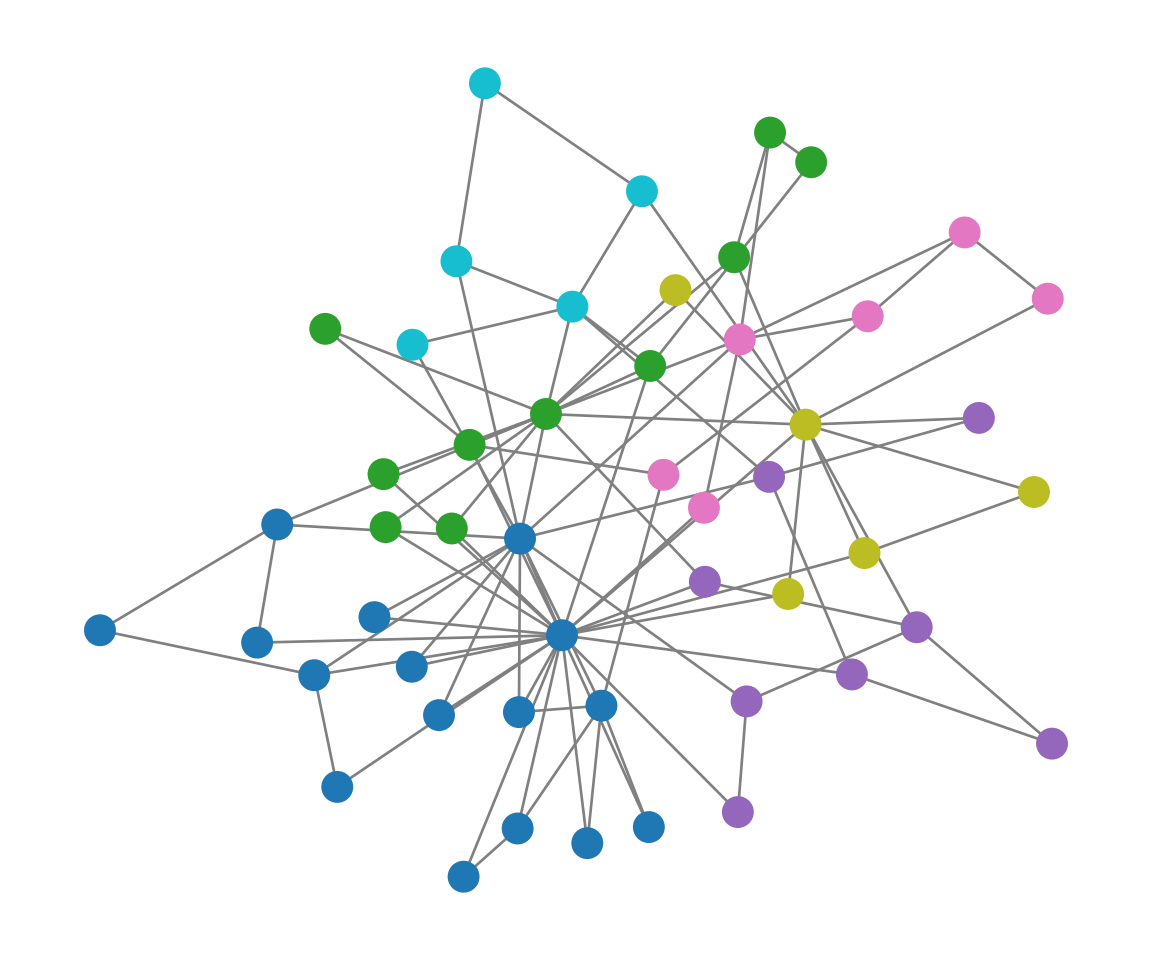
library(ggplot2)
# Coordenadas de los nodos
nodos <- data.frame(
x = c(0, 2, 1),
y = c(1.7, 1.7, 0),
label = c("1", "2", "3")
)
# Aristas (pares de nodos)
aristas <- data.frame(
x = c(0, 2, 1, 0, 2, 1),
y = c(1.7, 1.7, 0, 1.7, 1.7, 0),
xend = c(2, 1, 0, 1, 0, 2),
yend = c(1.7, 0, 1.7, 0, 1.7, 1.7)
)
ggplot() +
geom_segment(data = aristas, aes(x = x, y = y, xend = xend, yend = yend),
color = "gray30", linewidth = 1) +
geom_point(data = nodos, aes(x = x, y = y), size = 6, shape = 21, fill = "white") +
geom_text(data = nodos, aes(x = x, y = y, label = label), size = 5) +
coord_fixed() +
theme_void() +
theme(plot.margin = margin(10, 10, 10, 10))