# Instalamos librerías básicas para conectarnos a la API y manipular datos
%pip install -q requests pandas scikit-learn networkx matplotlib
# Importamos los módulos que usaremos
import os, time, math, requests, pandas as pd, numpy as np
import networkx as nx
import matplotlib.pyplot as plt
# Pedimos al usuario su clave API (una sola vez)
GOOGLE_API_KEY = os.environ.get("GOOGLE_API_KEY") or input("🔑 Pega tu GOOGLE_API_KEY: ").strip()Redes y grafos para estadística

En ciencia de datos moderna, una API (Application Programming Interface) es una puerta de acceso a datos reales en internet. Permite que nuestro programa (por ejemplo, en Python) “hable” con servicios externos como:
Google Maps / Places → lugares, reseñas, coordenadas.
Twitter o X → mensajes, usuarios, tendencias.
Spotify → canciones, artistas y estadísticas.
En vez de descargar un archivo estático (.csv o .xlsx), usamos peticiones web dinámicas (requests) que devuelven datos actualizados en formato JSON.
Una API = un puente entre tu código y una base de datos en línea.
Ejemplo: API de Google Places
La API de Google Places permite buscar lugares (cafés, restaurantes, parques, bibliotecas…) según una palabra clave y una ubicación geográfica.
Nos conectaremos al endpoint:
https://maps.googleapis.com/maps/api/place/textsearch/jsonque devuelve información en formato JSON, similar a esto:
{
"results": [
{
"name": "Café Amor Perfecto",
"rating": 4.6,
"user_ratings_total": 382,
"geometry": {"location": {"lat": 4.63, "lng": -74.06}},
"formatted_address": "Cra. 4 #66-46, Chapinero, Bogotá"
},
...
]
}Cada resultado representa un lugar real encontrado por Google.
Crear tu clave de API en Google Cloud
Para conectarte a los servicios de Google necesitas una API Key, que funciona como tu “credencial personal” de acceso.
Entra a 👉 https://console.cloud.google.com/
Crea un nuevo proyecto (o usa uno existente).
Ve a “APIs & Services → Library” y habilita la Places API.
Luego entra a “APIs & Services → Credentials → Create API key”.
Copia tu clave (
AIza...) y guárdala.(Opcional pero recomendado): Restringe su uso → solo “Places API”.
Google ofrece créditos gratuitos cada mes para uso educativo o personal.
Preparar el entorno en Python
Aquí instalamos los paquetes necesarios y configuramos nuestra clave. Cada parte está explicada con detalle 👇
requests: para hacer las peticiones web a la API de Google.pandas: para convertir los resultados JSON en tablas (DataFrames).networkx: para construir redes de relaciones entre lugares.matplotlib: para graficar las redes o mapas.os.environ.get(...): busca la clave guardada en tu entorno.Si no existe, el programa te pedirá pegarla manualmente:
🔑 Pega tu GOOGLE_API_KEY:Función para buscar lugares en Bogotá
Ahora sí, definimos la función gmaps_text_search() que:
Envía una búsqueda al endpoint de Google Places.
Descarga los resultados (nombre, rating, reseñas, coordenadas…).
Devuelve un DataFrame limpio con todos los lugares encontrados.
def gmaps_text_search(query="cafe", lat=4.7110, lon=-74.0721, radius=30000, region="co", max_pages=5, sleep_s=2.0):
"""
Busca lugares con Text Search en un área de Google Places.
Devuelve una tabla (DataFrame) con los resultados básicos.
- query: palabra clave (ej. 'cafe', 'restaurant', 'library')
- lat, lon: coordenadas del centro de búsqueda
- radius: radio de búsqueda en metros
- region: código de país ('co' = Colombia)
- max_pages: número máximo de páginas a recorrer (20 resultados por página)
- sleep_s: pausa entre páginas para no saturar el servidor
"""
url = "https://maps.googleapis.com/maps/api/place/textsearch/json"
params = {
"query": query,
"location": f"{lat},{lon}",
"radius": radius,
"region": region,
"key": GOOGLE_API_KEY
}
rows, page = [], 0
while page < max_pages:
r = requests.get(url, params=params, timeout=30)
data = r.json()
# Si hubo error, lo mostramos y detenemos
if data.get("status") not in ("OK", "ZERO_RESULTS"):
print("Error:", data.get("status"), data.get("error_message"))
break
# Extraemos la información de cada lugar
for p in data.get("results", []):
rows.append({
"place_id": p.get("place_id"),
"nombre": p.get("name"),
"rating": p.get("rating"),
"reseñas": p.get("user_ratings_total"),
"price_level": p.get("price_level"),
"lat": p.get("geometry", {}).get("location", {}).get("lat"),
"lon": p.get("geometry", {}).get("location", {}).get("lng"),
"address": p.get("formatted_address"),
"types": ",".join(p.get("types", []))
})
# Si hay más resultados, esperamos y pedimos la siguiente página
nxt = data.get("next_page_token")
if not nxt:
break
time.sleep(sleep_s)
params = {"pagetoken": nxt, "key": GOOGLE_API_KEY}
page += 1
return pd.DataFrame(rows)Buscar cafés en Bogotá
Ejecutamos nuestra función con una consulta simple:
df = gmaps_text_search(query="cafe bogota", max_pages=6)
df.shape, df.head(3)📊 Esto devolverá una tabla con columnas como:
| nombre | rating | reseñas | lat | lon | address |
|---|---|---|---|---|---|
| Catación Pública | 4.7 | 521 | 4.64 | -74.06 | Cra. 4 #66-46, Chapinero |
| Amor Perfecto | 4.5 | 415 | 4.63 | -74.07 | Teusaquillo |
| Varietale Café | 4.6 | 308 | 4.61 | -74.08 | La Candelaria |
# Guardar datos
# Supongamos que ya tienes el DataFrame df
df = gmaps_text_search(query="cafe bogota", max_pages=6)
# Guardar en un archivo CSV
df.to_csv("cafes_bogota.csv", index=False, encoding="utf-8")
# Confirmar
print("Archivo guardado como cafes_bogota.csv")🧩 NetworkX básico: nodos, aristas y atributos
Una red es una forma poderosa de representar relaciones entre entidades. En estadística, los nodos pueden ser observaciones (personas, lugares, variables), y las aristas representan una relación o vínculo entre ellos (amistad, proximidad, similitud…).
La librería networkx de Python nos permite crear, analizar y visualizar estas redes con facilidad.
🧱 Ejemplo introductorio: red de estudiantes y grupos
El siguiente ejemplo muestra cómo construir una red no dirigida donde los nodos son estudiantes y grupos de trabajo:
import networkx as nx
import matplotlib.pyplot as plt
# Creamos un grafo no dirigido (relaciones simétricas)
G = nx.Graph()
# --- Nodos ---
estudiantes = ["Ana", "Luis", "María", "Pedro"]
grupos = ["Grupo A", "Grupo B"]
# Agregamos los nodos con un atributo que indique su tipo
G.add_nodes_from(estudiantes, tipo="estudiante")
G.add_nodes_from(grupos, tipo="grupo")
# --- Aristas ---
# Cada estudiante pertenece a un grupo
G.add_edges_from([
("Ana", "Grupo A"),
("Luis", "Grupo A"),
("María", "Grupo B"),
("Pedro", "Grupo B"),
("Ana", "Luis") # conexión extra: colaboran entre sí
])
# --- Visualización ---
pos = nx.spring_layout(G, seed=3) # disposición visual
colores = ["skyblue" if G.nodes[n]["tipo"]=="estudiante" else "lightgreen" for n in G.nodes]
nx.draw(G, pos,
with_labels=True,
node_color=colores,
node_size=800,
edge_color="gray",
font_size=9)
plt.title("Red simple: estudiantes y grupos de trabajo")
plt.axis("off")
plt.show()Los nodos azules representan estudiantes.
Los nodos verdes son grupos de trabajo.
Las líneas (aristas) indican pertenencia o colaboración. Esta estructura es bipartita, porque une elementos de dos conjuntos diferentes.
🧮 Medidas básicas: grado y densidad
Podemos describir la red con métricas simples que cuantifican su conectividad.
# Grado de cada nodo (número de conexiones)
grados = dict(G.degree())
print("🔹 Grado de cada nodo:")
for nodo, g in grados.items():
print(f" {nodo}: {g}")
# Densidad: proporción de enlaces existentes sobre los posibles
densidad = nx.density(G)
print(f"\n🔹 Densidad total de la red = {densidad:.2f}")💬 Interpretación:
Los nodos con mayor grado son los más conectados.
Una densidad cercana a 1 indica una red muy compacta; una densidad baja sugiere pocas conexiones.
☕ Red empírica: cafés en Bogotá
- Preparar coordenadas para medir distancias geográficas
import pandas as pd
from sklearn.neighbors import NearestNeighbors
# Cargamos los datos locales (exportados o descargados de Google Places)
df = pd.read_csv("cafes_bogota.csv")
print(df.shape)
df.head(3)
#| echo: true
#| output: true
#| eval: false
coords = np.radians(df[["lat", "lon"]].dropna().to_numpy())Tomamos solo las columnas
latylon.Quitamos filas con faltantes (
dropna()), porque sin coordenadas no se puede calcular distancia.Convertimos a radianes (requisito matemático de la fórmula de haversine para distancias en esfera).
Lo pasamos a un arreglo numérico (
to_numpy()) para que lo use el modelo.
Por qué haversine: mide distancias sobre la Tierra (esférica), no en plano.
- Encontrar los k vecinos geográficos más cercanos de cada café
k = 6 # número de vecinos cercanos
nbrs = NearestNeighbors(n_neighbors=k+1, metric="haversine").fit(coords)
dist, idx = nbrs.kneighbors(coords)NearestNeighborses un algoritmo que, para cada punto, busca sus vecinos más próximos.Usamos
metric="haversine"para que las distancias sean geodésicas (en radianes).Pedimos
k+1porque el primer vecino de cada punto es él mismo; luego descartamos ese primero.distdevuelve las distancias (en radianes).idxdevuelve los índices de esos vecinos en el arreglo.
Después convertiremos esas distancias a kilómetros.
- Crear el grafo (nodos = cafés; aristas = cercanía)
G_cafe = nx.Graph()
for i, row in df.dropna(subset=["lat","lon"]).reset_index().iterrows():
G_cafe.add_node(i, nombre=row["nombre"], rating=row["rating"])- Creamos un grafo no dirigido (las conexiones son simétricas: A–B = B–A).
- Recorremos cada café con coordenadas válidas y lo agregamos como nodo.
- Guardamos como atributos el
nombrey elrating(útil para etiquetar o filtrar después).
Ojo: aquí ya hicimos un
dropna(igual que antes). Para evitar desalineaciones, conviene crear una copia filtrada y reiniciada una sola vez y usarla en todo el proceso (te dejo eso abajo en el bloque “versión robusta”).
- Añadir aristas (con peso = distancia en km)
R = 6371 # radio de la Tierra (km)
for i in range(len(coords)):
for jpos in idx[i,1:]:
j = int(jpos)
d_km = dist[i, np.where(idx[i]==jpos)[0][0]] * R
G_cafe.add_edge(i, j, weight=d_km)Res el radio de la Tierra en kilómetros.Para cada café
i, tomamos sus vecinos excepto él mismo (idx[i,1:]).Convertimos la distancia de radianes a km multiplicando por
R.Creamos una arista entre
iyjy guardamosweight=d_km(la distancia). Así luego puedes filtrar, colorear o medir con base en la distancia real.
- Posiciones para dibujar (proyección plana y simple)
x = (df["lon"] - df["lon"].min()) / (df["lon"].max() - df["lon"].min())
y = (df["lat"] - df["lat"].min()) / (df["lat"].max() - df["lat"].min())
pos = {i:(xk, yk) for i,(xk, yk) in enumerate(zip(x, y))}Normalizamos
lonylata [0,1] para tener una caja de dibujo.Creamos un diccionario
poscon la posición de cada nodo.Importante: si
dfaquí incluye filas sin coordenadas (o en distinto orden) que no están en el grafo, habrá desajuste. Por eso, lo correcto es usar la misma versión filtrada que usamos al crear nodos y vecinos.
Finalmente…
import numpy as np
import pandas as pd
from sklearn.neighbors import NearestNeighbors
# Cargamos los datos locales (exportados o descargados de Google Places)
df = pd.read_csv("cafes_bogota.csv")
print(df.shape)
df.head(3)
import numpy as np
# Convertimos coordenadas a radianes para usar la distancia haversine
coords = np.radians(df[["lat", "lon"]].dropna().to_numpy())
k = 6 # número de vecinos cercanos
# Modelo de vecinos más cercanos
nbrs = NearestNeighbors(n_neighbors=k+1, metric="haversine").fit(coords)
dist, idx = nbrs.kneighbors(coords)
# Grafo geográfico
G_cafe = nx.Graph()
for i, row in df.dropna(subset=["lat","lon"]).reset_index().iterrows():
G_cafe.add_node(i, nombre=row["nombre"], rating=row["rating"])
R = 6371 # radio de la Tierra (km)
for i in range(len(coords)):
for jpos in idx[i,1:]:
j = int(jpos)
d_km = dist[i, np.where(idx[i]==jpos)[0][0]] * R
G_cafe.add_edge(i, j, weight=d_km)
# Dibujamos la red aproximando posiciones geográficas
x = (df["lon"] - df["lon"].min()) / (df["lon"].max() - df["lon"].min())
y = (df["lat"] - df["lat"].min()) / (df["lat"].max() - df["lat"].min())
pos = {i:(xk, yk) for i,(xk, yk) in enumerate(zip(x, y))}
plt.figure(figsize=(6,5))
nx.draw(G_cafe, pos,
node_size=30,
node_color="tomato",
edge_color="gray",
with_labels=False)
plt.title("Red de cafés en Bogotá (k vecinos más cercanos)")
plt.axis("off")
plt.show()Cada nodo representa un establecimiento.
Las aristas indican cercanía geográfica, lo que puede interpretarse como competencia o interacción espacial.
☕ Mapa de cafés en Bogotá con color según su calificación
import folium
# 1️⃣ Crear el mapa base centrado en Bogotá
m = folium.Map(location=[4.65, -74.07], zoom_start=12)📍 Esto genera el mapa base de Bogotá, con un nivel de zoom medio (zoom_start=12) para ver los barrios.
Folium utiliza OpenStreetMap por defecto, de modo que es gratuito y de alta resolución.
# 2️⃣ Función para asignar color según el rating
def color_rating(rating):
if rating >= 4.5:
return "green" # excelente ☘️
elif rating >= 3.5:
return "orange" # bueno ☕
else:
return "red" # bajo 😬💡 Aquí creamos una función auxiliar que clasifica cada calificación (rating) en tres niveles:
- Verde: cafés con valoración ⭐4.5 o superior.
- Naranja: cafés entre ⭐3.5 y ⭐4.4.
- Rojo: cafés con valoración inferior a ⭐3.5.
Esta simple regla convierte un número en un mensaje visual.
# 3️⃣ Agregar cada café como marcador circular
for _, r in df.iterrows():
folium.CircleMarker(
location=[r.lat, r.lon],
radius=6,
color=color_rating(r.rating), # borde del círculo
fill=True,
fill_color=color_rating(r.rating), # color interno
fill_opacity=0.85,
popup=f"{r['nombre']} ⭐{r['rating']} ({r['reseñas']} reseñas)"
).add_to(m)df.iterrows()recorre fila por fila del DataFrame con los datos.folium.CircleMarker()dibuja un punto circular en el mapa.color_rating(r.rating)usa la función anterior para definir el color del punto según el nivel de satisfacción del café.popupcrea una pequeña ventana emergente con:
Nombre del café ⭐Calificación (n reseñas)Por ejemplo:
“Café Quindío ⭐4.7 (152 reseñas)”
# 4️⃣ Mostrar el mapa
m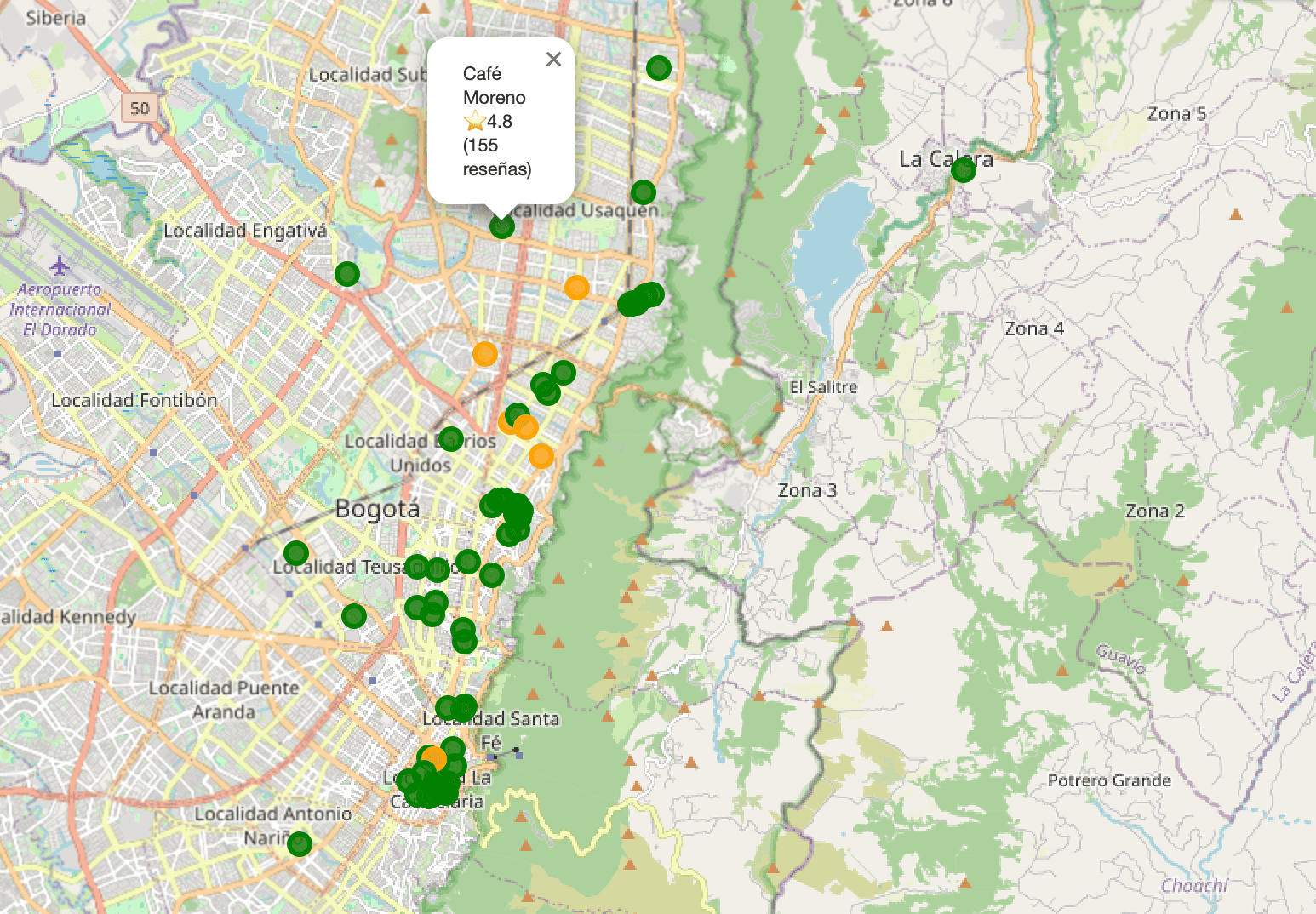
Esto renderiza el mapa interactivo directamente en el notebook. Podrás:
- Hacer zoom con el mouse.
- Clickear cada punto para ver su información.
- Interpretar visualmente qué zonas concentran mejores valoraciones (más puntos verdes).
Grado (degree) de cada café
Idea: en el grafo no dirigido
G_cafe, el grado de un nodo es el número de vecinos conectados a ese café (cuántos “cercanos” le enlazaste con k-NN).
import networkx as nx
import pandas as pd
# Si ya creaste G_cafe con tus aristas k-NN, aquí obtenemos los grados:
deg_dict = dict(G_cafe.degree()) # {nodo: grado}
# (Opcional) Pasarlo a DataFrame alineado con df:
deg_df = (pd.Series(deg_dict, name="grado")
.rename_axis("node_id")
.reset_index())
# Aseguramos el mismo orden que df y anexamos la columna "grado"
df_reset = df.dropna(subset=["lat","lon"]).reset_index(drop=True).copy()
df_reset["grado"] = df_reset.index.map(deg_dict).fillna(0).astype(int)Notas didácticas:
En un k-NN no dirigido y “simétrico”, el grado típico ronda k (puede variar por duplicaciones o bordes del área).
G_cafe.degree()cuenta aristas incidentes; es grado simple (sin ponderar).
Densidad de la red (global)
Idea: la densidad mide qué tan cerca está tu grafo de ser “completo”. Fórmula (no dirigido, sin lazos): [ = ] En NetworkX:
nx.density(G).
densidad = nx.density(G_cafe)
n = G_cafe.number_of_nodes()
m = G_cafe.number_of_edges()
print(f"Nodos: {n} | Aristas: {m} | Densidad: {densidad:.4f}")
# (Extra) Estadísticas rápidas de grado
import numpy as np
grados = np.fromiter(deg_dict.values(), dtype=int)
print(f"Grado medio: {grados.mean():.2f} | Mediana: {np.median(grados):.0f} | Máx: {grados.max()}")Lectura rápida:
En k-NN, si k es pequeño comparado con n, la densidad será baja (¡normal en grafos espaciales!).
Sirve para explicar por qué los grafos reales (de proximidad) no son completos.
La red de cafés en Bogotá tiene una estructura moderadamente dispersa: cada café se conecta con unos 8 vecinos, lo que refleja la cercanía local sin saturar la red. La densidad del 13 % confirma que solo una fracción pequeña de las posibles conexiones se materializa, y algunos puntos alcanzan grados más altos, indicando zonas de concentración de cafés o puntos estratégicos.