Comunidades y correlaciones en redes
Detección de grupos, homofilia y relación grupo–atributos
Aprender a detectar comunidades en grafos y relacionarlas con atributos (homofilia).
Usaremos la modularidad (Q) como medida de “calidad” del particionado y estudiaremos:
Greedy modularity (
networkx.algorithms.community).Asortatividad por atributo (tendencia a conectarse con “iguales”).
Relación comunidad ↔︎ variable (tablas/estadística básica).
1 Ejemplo simple: comunidades visibles y homofilia
Creamos un grafo con dos comunidades claras y un par de puentes.
Asignamos un atributo categórico (grupo = A/B) y uno numérico (rendimiento).
import networkx as nx
import numpy as np
from networkx.algorithms import community as nxcom
# Grafo con dos grupos densos y algunos puentes
G = nx.Graph()
G.add_edges_from([
# Comunidad A (nodos 'A1'...'A6')
("A1","A2"),("A1","A3"),("A2","A3"),("A2","A4"),("A3","A5"),("A4","A5"),("A5","A6"),
# Comunidad B (nodos 'B1'...'B6')
("B1","B2"),("B1","B3"),("B2","B3"),("B2","B4"),("B3","B5"),("B4","B5"),("B5","B6"),
# Puentes entre A y B
("A3","B3"), ("A6","B1")
])
# Atributos
for n in G.nodes():
G.nodes[n]["grupo"] = "A" if n.startswith("A") else "B"
# Atributo numérico “rendimiento” (más alto en A, más bajo en B para inducir homofilia)
rng = np.random.default_rng(42)
for n in G.nodes():
base = 80 if G.nodes[n]["grupo"]=="A" else 70
G.nodes[n]["rendimiento"] = float(base + rng.normal(0, 3))
print(f"Nodos: {G.number_of_nodes()}, Aristas: {G.number_of_edges()}")1.1 Detección de comunidades (greedy) y modularidad Q
from networkx.algorithms import community as nxcom
coms = nxcom.greedy_modularity_communities(G)
Q = nxcom.modularity(G, coms)
print("Comunidades detectadas:", [sorted(list(c)) for c in coms])
print(f"Modularidad Q: {Q:.3f}")Lectura.
Q cercano a 0.3–0.5 suele indicar comunidades claras.
Esperamos dos comunidades alineadas con A/B (no siempre perfectas por los puentes).
1.2 Asortatividad por atributo (homofilia)
Asortatividad categórica: ¿tienden los nodos a conectarse con el mismo grupo?
# Mapeo categórico a etiquetas enteras
grupos = {n: (0 if G.nodes[n]["grupo"]=="A" else 1) for n in G.nodes()}
for n,val in grupos.items():
G.nodes[n]["grupo_code"] = val
r_cat = nx.attribute_assortativity_coefficient(G, "grupo_code")
print(f"Asortatividad por grupo (categórica): r = {r_cat:.3f}")Asortatividad numérica: ¿se conectan nodos con rendimiento similar?
# Para numérica, usamos el coeficiente de “atributo numérico” emparejando extremos de aristas
# (NetworkX no trae directo el coeficiente numérico global; hacemos correlación sobre extremos)
import pandas as pd
pairs = []
for u, v in G.edges():
pairs.append((G.nodes[u]["rendimiento"], G.nodes[v]["rendimiento"]))
df_pairs = pd.DataFrame(pairs, columns=["x","y"])
num_corr = df_pairs.corr().loc["x","y"]
print(f"Asociación numérica en extremos de aristas (Pearson x~y): ρ = {num_corr:.3f}")Interpretación esperada.
r_cat > 0: homofilia por grupo (A–A y B–B prevalecen).ρ > 0: vecinos con rendimientos similares.
1.3 Visualización rápida por comunidad
import matplotlib.pyplot as plt
import matplotlib.cm as cm
num_comm = len(coms)
colors = cm.get_cmap("tab20", num_comm)
pos = nx.spring_layout(G, seed=7, k=0.8)
plt.figure(figsize=(7,5))
for cid, nodes in enumerate(coms):
nx.draw_networkx_nodes(G, pos,
nodelist=list(nodes),
node_color=[colors(cid)],
node_size=600, label=f"Comunidad {cid}")
nx.draw_networkx_edges(G, pos, alpha=0.3)
nx.draw_networkx_labels(G, pos, font_size=10)
plt.title(f"Red simple — Comunidades (Q={Q:.2f})")
plt.axis("off")
plt.legend(markerscale=0.7)
# plt.show()2 Aplicación: cafés en Bogotá (clusters y correlaciones)
Partimos del CSV con lat, lon, nombre, rating y construimos la red por k-vecinos (Haversine). Luego detectamos comunidades, medimos Q, evaluamos asortatividad por rating alto/bajo y dibujamos los clusters (tanto como grafo abstracto como mapa).
import pandas as pd
import numpy as np
import networkx as nx
from sklearn.neighbors import NearestNeighbors
# 2.1 Cargar datos y construir G_cafe (k-NN)
df = pd.read_csv("cafes_bogota.csv")
coords = np.radians(df[["lat","lon"]].dropna().to_numpy())
k = 6
nbrs = NearestNeighbors(n_neighbors=k+1, metric="haversine").fit(coords)
dist, idx = nbrs.kneighbors(coords)
G_cafe = nx.Graph()
rows = df.dropna(subset=["lat","lon"]).reset_index(drop=True)
for i, row in rows.iterrows():
G_cafe.add_node(i, nombre=row["nombre"], rating=float(row["rating"]), lat=float(row["lat"]), lon=float(row["lon"]))
for i in range(len(coords)):
for jpos in idx[i,1:]:
j = int(jpos)
if i != j:
# Peso=distancia haversine (radianes); no es necesario para modularidad pero útil si analizas rutas
d = float(dist[i, np.where(idx[i]==jpos)[0][0]])
G_cafe.add_edge(i, j, weight=d)
print(f"Nodos: {G_cafe.number_of_nodes()} | Aristas: {G_cafe.number_of_edges()}")2.1 Detección de comunidades y modularidad (clusters)
from networkx.algorithms import community as nxcom
coms_cafe = nxcom.greedy_modularity_communities(G_cafe)
Q_cafe = nxcom.modularity(G_cafe, coms_cafe)
# Asignar id de comunidad a cada nodo
comm_id_of = {}
for cid, C in enumerate(coms_cafe):
for u in C: comm_id_of[u] = cid
nx.set_node_attributes(G_cafe, comm_id_of, "community")
print(f"Comunidades detectadas: {len(coms_cafe)} | Q = {Q_cafe:.3f}")
print("Tamaños por comunidad:", [len(C) for C in coms_cafe])2.2 Relación comunidad ↔︎ rating (homofilia / asortatividad)
2.2.1 Asortatividad categórica por “rating alto” (≥ 4.5)
# Binaria: high_rating = 1 si rating ≥ 4.5, else 0
for n in G_cafe.nodes():
G_cafe.nodes[n]["high_rating"] = int(G_cafe.nodes[n]["rating"] >= 4.5)
r_high = nx.attribute_assortativity_coefficient(G_cafe, "high_rating")
print(f"Asortatividad por high_rating (≥4.5): r = {r_high:.3f}")Lectura: r > 0 sugiere homofilia: cafés bien valorados tienden a estar conectados con otros bien valorados.
2.2.2 Diferencias de rating por comunidad (tabla resumen)
import pandas as pd
data = []
for cid, C in enumerate(coms_cafe):
vals = [G_cafe.nodes[u]["rating"] for u in C]
data.append({"community": cid, "n": len(vals), "rating_mean": np.mean(vals), "rating_sd": np.std(vals)})
tab = pd.DataFrame(data).sort_values("rating_mean", ascending=False)
print(tab)Interpretación: compara medias de rating por grupo; ayuda a ver si los clusters reflejan zonas de alta calidad.
2.3 Visualizar clusters (grafo) y mapa (Folium)
2.3.1 Grafo coloreado por comunidad
import matplotlib.pyplot as plt
import matplotlib.cm as cm
num_comm = len(coms_cafe)
colors = cm.get_cmap("tab20", num_comm)
# Layout de resorte sobre el grafo de cafés
pos = nx.spring_layout(G_cafe, seed=12, k=0.35)
plt.figure(figsize=(9,7))
for cid, nodes in enumerate(coms_cafe):
nx.draw_networkx_nodes(G_cafe, pos,
nodelist=list(nodes),
node_color=[colors(cid)],
node_size=40, label=f"Comunidad {cid}")
nx.draw_networkx_edges(G_cafe, pos, alpha=0.15)
plt.title(f"Red de cafés — Clusters por modularidad (Q={Q_cafe:.2f})")
plt.axis("off")
plt.legend(markerscale=3)
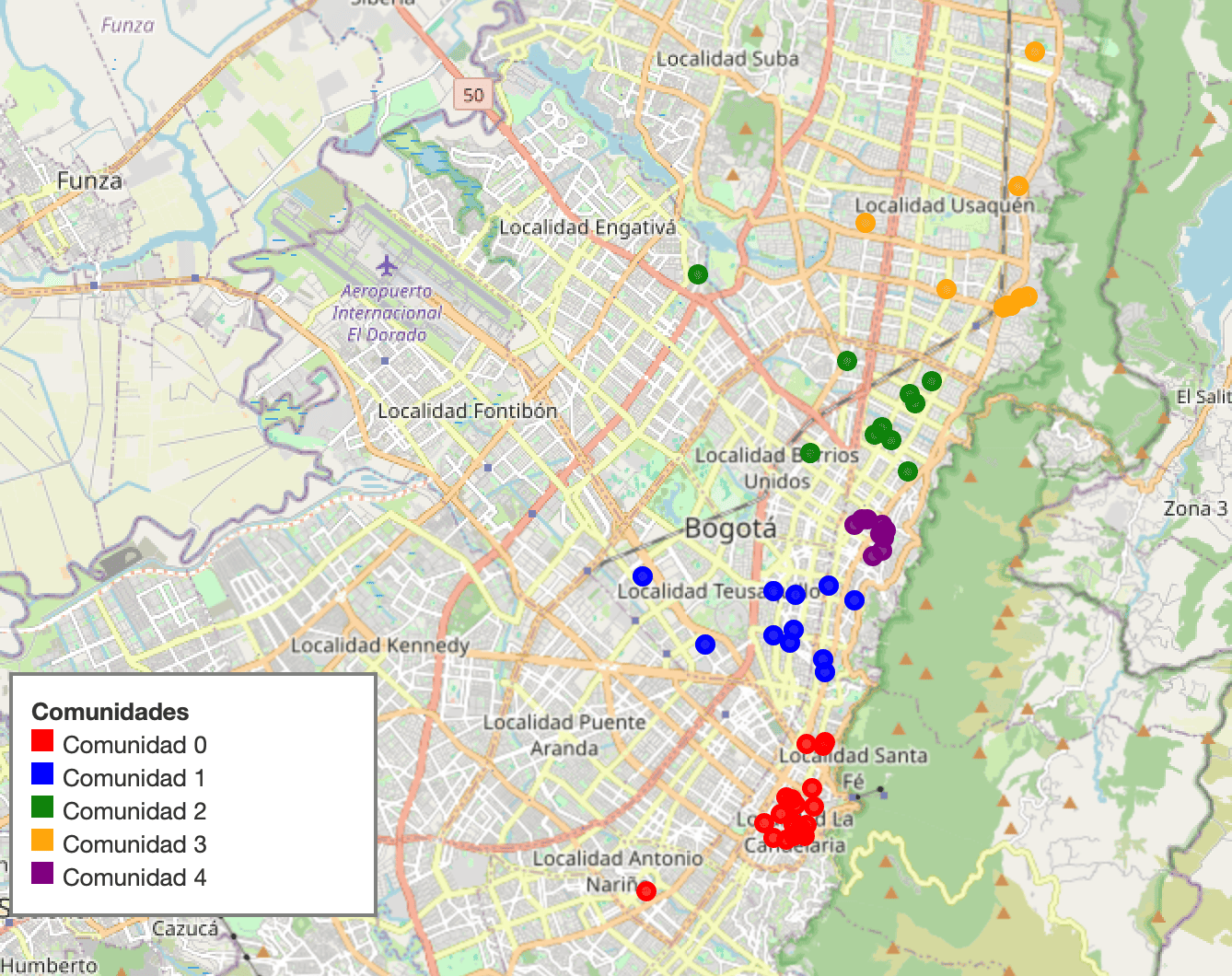
# plt.show()2.3.2 Mapa Folium coloreado por comunidad (clusters espaciales)
import folium
palette = [
"red","blue","green","orange","purple","darkred","lightblue","darkgreen",
"cadetblue","pink","lightgreen","gray","black","lightgray"
]
def color_for_comm(cid): return palette[cid % len(palette)]
m = folium.Map(location=[4.65, -74.07], zoom_start=12)
for n in G_cafe.nodes():
c = G_cafe.nodes[n]["community"]
folium.CircleMarker(
location=[G_cafe.nodes[n]["lat"], G_cafe.nodes[n]["lon"]],
radius=4,
color=color_for_comm(c),
fill=True,
fill_color=color_for_comm(c),
fill_opacity=0.85,
popup=f"{G_cafe.nodes[n]['nombre']}<br>Comunidad: {c} | ⭐ {G_cafe.nodes[n]['rating']}"
).add_to(m)
# Leyenda
legend_html = "<div style='position: fixed; bottom: 50px; left: 50px; width: 200px; background-color: white; border:2px solid grey; z-index:9999; font-size:13px; padding: 10px;'><b>Comunidades</b><br>"
for cid in range(num_comm):
legend_html += f"<i style='background:{color_for_comm(cid)};width:12px;height:12px;float:left;margin-right:5px'></i> Comunidad {cid}<br>"
legend_html += "</div>"
m.get_root().html.add_child(folium.Element(legend_html))
m2.4 Comparar modularidad Q al variar la construcción de la red
Explora cómo cambia Q al variar k (densidad) en la red k-NN.
def build_knn_graph(coords_radians, k):
nbrs = NearestNeighbors(n_neighbors=k+1, metric="haversine").fit(coords_radians)
dist, idx = nbrs.kneighbors(coords_radians)
Gk = nx.Graph()
for i in range(len(coords_radians)):
Gk.add_node(i)
for i in range(len(coords_radians)):
for jpos in idx[i,1:]:
j = int(jpos)
if i!=j: Gk.add_edge(i,j)
return Gk
Ks = [4, 6, 8, 10]
Q_vals = []
for kk in Ks:
Gk = build_knn_graph(coords, kk)
coms_k = nxcom.greedy_modularity_communities(Gk)
Q_vals.append(nxcom.modularity(Gk, coms_k))
print("k:", Ks)
print("Q(k):", [round(q,3) for q in Q_vals])Lectura: en general, Q tiende a bajar si saturas la red (k muy alto) porque las fronteras entre grupos se difuminan; con k muy bajo puedes romper la conectividad y también perjudicar Q.
La modularidad (Q) sintetiza cuán clara es la división de la red en comunidades densas y separadas.
La asortatividad cuantifica si hay homofilia (uniones entre “iguales”), ya sea por categorías (rating alto/bajo) o por valores numéricos (rendimiento).
En la red de cafés, los clusters detectados se pueden mapear y relacionar con atributos (rating), ayudando a comprender patrones urbanos de concentración/dispersión.
Nodos: 60 (cafés o unidades del estudio).
Aristas: 240 (relaciones/vecindades según tu regla de construcción).
Grado medio: ( {k} = = = 8 ).
Densidad aproximada: ( ). Interpretación: red moderadamente esparcida (no completa), cada nodo se conecta en promedio con 8 otros. Suficiente estructura para hablar de comunidades sin estar “sobreconectada”.
Comunidades detectadas: 5 con tamaños [20, 11, 10, 10, 9].
Modularidad (Q): 0.649 (alta).
Interpretación: (Q) indica estructura comunitaria fuerte: los nodos se conectan mucho más dentro de su grupo que entre grupos. En términos prácticos (según tu criterio de arista: co-reseña, co-visita o cercanía), hay bloques temáticos/territoriales bien definidos.
Promedios reportados:
- Comunidad 1 (n=11): ({r}=4.745), (sd=0.130) — la más alta.
- Comunidad 0 (n=20): ({r}=4.695), (sd=0.150) — grande y con buen promedio.
- Comunidad 3 (n=10): ({r}=4.630), (sd=0.179).
- Comunidad 4 (n=9): ({r}=4.600), (sd=0.047) — muy homogénea (baja variabilidad).
- Comunidad 2 (n=10): ({r}=4.540), (sd=0.169) — la más baja, pero aún alta en términos absolutos.
Hay gradiente suave entre comunidades (4.54 → 4.75). La Comunidad 1 destaca en calidad media; la Comunidad 4 es muy consistente (poca dispersión). La Comunidad 0 combina tamaño y buen rating → buen “cluster ancla”.
2.4.0.1 Asortatividad por “rating ≥ 4.5”
Coeficiente (r=0.107) (ligeramente positivo).
Interpretación: homofilia leve: locales con rating alto (≥4.5) tienden a conectarse un poco más entre sí que con los de menor rating. No es fuerte, pero existe una tendencia a la “agrupación de calidad”.
Estructura: Red poco densa pero con grupos bien marcados (Q alto).
Calidad por comunidad: Diferencias moderadas; destacar Comunidad 1 (mejor promedio) y Comunidad 4 (calidad estable).
Asortatividad: “Los buenos se juntan con buenos” un poco — suficiente para hablar de segmentación suave por calidad.
Si esto fuera recomendación/marketing: priorizar Comunidad 1 para “best-of”, Comunidad 0 para cobertura (más grande), Comunidad 4 para experiencias consistentes.
Para exploración: buscar puentes (aristas entre comunidades) donde la calidad alta no esté bien conectada (oportunidad de descubrimiento).
3 ¿Cómo recomendar cafés?
En esta parte aprendemos a recomendar cafés similares
usando información como su rating, nivel de precio,
reseñas y tipos de servicio.
La clave es transformar cada café en un vector numérico,
para luego comparar qué tan cercanos son entre sí.
3.1 Cargar y preparar los datos
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, MultiLabelBinarizer
from sklearn.metrics.pairwise import cosine_similarity
tmp = pd.read_csv("cafes_bogota.csv").copy()
# Rellenar faltantes en nivel de precio
tmp["price_level"] = tmp["price_level"].fillna(tmp["price_level"].median())Cada café tiene datos sobre su rating, reseñas, y su tipo (types), que indica si es cafetería, panadería, restaurante, etc.
3.2 Codificar los tipos (One-Hot Encoding)
La columna types tiene etiquetas separadas por comas. Usamos MultiLabelBinarizer para crear variables binarias (0/1) según los tipos de lugar.
mlb = MultiLabelBinarizer()
cats = tmp["types"].fillna("").str.lower().str.split(",")
cats_ohe = pd.DataFrame(
mlb.fit_transform(cats),
columns=mlb.classes_,
index=tmp.index
)Así, obtenemos columnas como cafe, bakery, restaurant, etc. ✅ 1 si el café pertenece a ese tipo, 0 si no.
3.3 Escalar variables numéricas
Las variables como rating, reseñas y price_level tienen diferentes escalas. Usamos MinMaxScaler para normalizarlas a ([0,1]).
num = tmp[["rating", "price_level", "reseñas"]].fillna(0)
num_scaled = pd.DataFrame(
MinMaxScaler().fit_transform(num),
columns=num.columns,
index=tmp.index
)👉 Esto evita que las reseñas (con valores grandes) dominen la similitud.
3.4 Crear la matriz combinada
Unimos los datos numéricos y categóricos para construir un vector completo de cada café ☕.
X = pd.concat([num_scaled, cats_ohe], axis=1).valuesCada fila de X representa un café como vector numérico: \[
\text{café}_i = [\text{rating}, \text{precio}, \text{reseñas}, \text{tipos...}]
\]
3.5 Calcular la similitud coseno
La similitud del coseno mide el ángulo entre vectores. Dos cafés son parecidos si sus vectores apuntan en la misma dirección.
sim = cosine_similarity(X)
nombres = tmp["nombre"].tolist()\[ \text{sim}(i,j) = \frac{X_i \cdot X_j}{||X_i|| , ||X_j||} \]
Valores cercanos a 1 indican cafés muy similares 🔍
3.6 Función de recomendación
Creamos una función que devuelve los k cafés más parecidos.
def recomendar(cafe, k=5):
"""
Retorna los k cafés más similares según rating, precio, reseñas y tipos.
"""
if cafe not in nombres:
print("⚠️ Café no encontrado.")
return []
i = nombres.index(cafe)
order = sorted(enumerate(sim[i]), key=lambda t: t[1], reverse=True)
return [(nombres[j], float(score)) for j, score in order[1:k+1]]Aplicamos la función al café “Érase una vez café de especialidad” para obtener los lugares más similares en perfil:
ejemplo = "Érase una vez café de especialidad"
pd.DataFrame(recomendar(ejemplo, 5),
columns=["Café recomendado", "Similitud"])| Café recomendado | Similitud |
|---|---|
| Gracia - Coffee & Brunch | 0.999763 |
| Café del Mercado | 0.999510 |
| Café Cécile | 0.998227 |
| Mundano Coffee Shop | 0.998116 |
| Presente Café | 0.997760 |
✨ Todos comparten un estilo de café de especialidad, ambiente similar y nivel de precios comparable.
Los valores cercanos a 1 indican gran similitud: mismo tipo de lugar, precios similares y reseñas parecidas.
Este enfoque es la base de los sistemas de recomendación, como los que usan Netflix, Spotify o TripAdvisor.
En nuestro caso, hemos creado un recomendador de cafés a partir de datos reales de Bogotá. 🌆☕
3.7 Código completo
# ============================================================
# 🧪 Vectorizar cafés y generar recomendaciones por similitud
# ============================================================
%pip install -q scikit-learn
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, MultiLabelBinarizer
from sklearn.metrics.pairwise import cosine_similarity
# ------------------------------------------------------------
# 1️⃣ Cargar datos y preparar columnas
# ------------------------------------------------------------
tmp = pd.read_csv("cafes_bogota.csv").copy()
# Rellenar faltantes en nivel de precio
tmp["price_level"] = tmp["price_level"].fillna(tmp["price_level"].median())
# ------------------------------------------------------------
# 2️⃣ Codificar tipos como variables binarias (One-hot)
# ------------------------------------------------------------
mlb = MultiLabelBinarizer()
cats = tmp["types"].fillna("").str.lower().str.split(",")
cats_ohe = pd.DataFrame(
mlb.fit_transform(cats),
columns=mlb.classes_,
index=tmp.index
)
# ------------------------------------------------------------
# 3️⃣ Escalar variables numéricas a [0,1]
# ------------------------------------------------------------
num = tmp[["rating", "price_level", "reseñas"]].fillna(0)
num_scaled = pd.DataFrame(
MinMaxScaler().fit_transform(num),
columns=num.columns,
index=tmp.index
)
# ------------------------------------------------------------
# 4️⃣ Combinar todas las variables en una matriz única
# ------------------------------------------------------------
X = pd.concat([num_scaled, cats_ohe], axis=1).values
# Calcular similitud coseno entre todos los cafés
sim = cosine_similarity(X)
nombres = tmp["nombre"].tolist()
# ------------------------------------------------------------
# 5️⃣ Función de recomendación
# ------------------------------------------------------------
def recomendar(cafe, k=5):
"""
Retorna los k cafés más similares según rating, precio, reseñas y tipos.
"""
if cafe not in nombres:
print("⚠️ Café no encontrado.")
return []
i = nombres.index(cafe)
order = sorted(enumerate(sim[i]), key=lambda t: t[1], reverse=True)
return [(nombres[j], float(score)) for j, score in order[1:k+1]]
# ------------------------------------------------------------
# 6️⃣ Ejemplo de uso
# ------------------------------------------------------------
ejemplo = nombres[0]
print(f"Recomendaciones similares a: {ejemplo}\n")
pd.DataFrame(recomendar(ejemplo, 5), columns=["Café recomendado", "Similitud"])